Sample Solutions for Assignment 1 (44 marks)
Due Friday, Feb. 4,
- (6 marks) Exercise 1.1
a. Dictionary
definitions of intelligence talk about “the capacity to acquire and
apply knowledge” or “the faculty of thought and reason” or “the ability to
comprehend and profit from experience.” These are all reasonable answers, but
if we want something quantifiable we would use something like “the ability to
apply knowledge in order to perform better in an environment.”
b. We define artificial intelligence as
the study and construction of agent programs that perform well in a given
environment, for a given agent architecture.
c. We define an agent as an entity that
takes action in response to percepts from an environment.
- (6
marks) Exercise 2.4


- (6 marks) Exercise 2.9 (for the vacuum-cleaner world depicted in Figure 2.2 and specified on page 36).
- No. The agent keeps moving backwards
and forwards even after the world is clean. It is better to do NoOp once the world is clean (the chapter
says this). Now, since the agent’s percept doesn’t say whether the other
square is clean, it would seem that the agent must have some memory to
say whether the other square has already been cleaned. To make this
argument rigorous is more difficult—for example,
could the agent arrange things so that it would only be in a clean left
square when the right square was already clean? As a general strategy, an
agent can use the environment itself as a form of external
memory—a common technique for humans who use things like appointment
calendars and knots in handkerchiefs. In this particular case, however,
that is not possible. Consider the reflex actions for [A, Clean] and [B, Clean].
If either of these is NoOp, then the agent will fail in the case
where that is the initial percept but the other square is dirty; hence,
neither can be NoOp and therefore the simple reflex agent
is doomed to keep moving. In general, the problem with reflex agents is
that they have to do the same thing in situations that look the same,
even when the situations are actually quite different. In the vacuum
world this is a big liability, because every interior square (except
home) looks either like a square with dirt or a square without dirt.
- See answer to a.
- In this case, a simple reflex agent can
be perfectly rational. The agent can consist of a table with eight
entries, indexed by percept, that specifies an
action to take for each possible state. After the agent acts, the world
is updated and the next percept will tell the agent what to do next. For
larger environments, constructing a table is infeasible. Instead, the
agent could run one of the optimal search algorithms in Chapters 3 and 4
and execute the first step of the solution sequence. Again, no internal
state is required, but it would help to be able to store the
solution sequence instead of recomputing it for
each new percept.
- (4 marks) Exercise 2.12
- For a
reflex agent, this presents no additional challenge, because the
agent will continue to Suck as long as the current location remains
dirty. For an agent that constructs a sequential plan, every Suck action would need to be replaced by “Suck until clean.” If the dirt sensor can be
wrong on each step, then the agent might want to wait for a few steps to
get a more reliable measurement before deciding whether to Suck or move on to a new square. Obviously,
there is a trade-off because waiting too long means that dirt remains on
the floor (incurring a penalty), but acting immediately risks either
dirtying a clean square or ignoring a dirty square (if the sensor is
wrong). A rational agent must also continue touring and checking the
squares in case it missed one on a previous tour (because of bad sensor
readings). it is not immediately obvious how the
waiting time at each square should change with each new tour. These
issues can be clarified by experimentation, which may suggest a general
trend that can be verified mathematically. This problem
is a partially observable Markov decision process—see Chapter 17.
Such problems are hard in general, but some special cases may yield to
careful analysis.
- In this
case, the agent must keep touring the squares indefinitely. The
probability that a square is dirty increases monotonically with the time
since it was last cleaned, so the rational strategy is, roughly speaking,
to repeatedly execute the shortest possible tour of all squares. (We say
“roughly speaking” because there are complications caused by the fact
that the shortest tour may visit some squares twice, depending on the geography.)
This problem is also a partially observable Markov decision process.
- (6 marks) Exercise 3.4 (change 8-puzzle to 15-puzzle on a 4 ×4 board).
For a given puzzle configuration, let N denote the sum of the total number of inversions and the row number of the empty square. Then (N mod 2) is invariant under any legal move. In other words, after a legal move an odd N remains odd whereas an even N remains even.
First of all, sliding a counter horizontally changes neither the total number of inversions nor the row number of the empty square. Therefore let's consider sliding a counter vertically.
Let's assume, for example, that the counter a is located directly over the empty square. Sliding it down changes the parity of the row number of the empty square. Now consider the total number of inversions. The move only affects relative positions of counters a, b, c, and d. If none of the b, c, d caused an inversion relative to a (i.e., all three are larger than a) then after sliding one gets three (an odd number) of additional inversions. If one of the three is smaller than a, then before the move b,c, and d contributed a single inversion (relative to a) whereas after the move they'll be contributing two inversions - a change of 1, also an odd number. Two additional cases obviously lead to the same result. Thus the change in the sum N is always even. This is precisely what we have set out to show.
- (4
marks) Exercise 3.7 a. b
a. Initial state: No regions colored.
Goal test:
All regions colored, and no two adjacent regions have the same color.
Successor
function: Assign a color to a region.
Cost
function: Number of assignments.
b. Initial state: As described in the text.
Goal test:
Monkey has bananas.
Successor
function: Hop on crate; Hop off crate; Push crate from one spot to another;
Walk from one spot to another; grab bananas (if standing on crate).
Cost function: Number of actions.
- (6 marks) Exercise 3.9 (no need to implement it)
a. Here is one possible representation: A state
is a six-tuple of integers listing the number of
missionaries, cannibals, and boats on the first side, and then the second side
of the river. The goal is a state with 3 missionaries and 3 cannibals on the
second side. The cost function is one per action, and the successors of a state
are all the states that move 1 or 2 people and 1 boat from one side to another.
b. The search space is small, so any optimal
algorithm works. It suffices to eliminate moves that circle back to the state
just visited. From all but the first and last states, there is only one other
choice.
c. It is not obvious that almost all moves are
either illegal or revert to the previous state. There is a feeling of a large
branching factor, and no clear way to proceed.
- (2 marks) Exercise 3.13
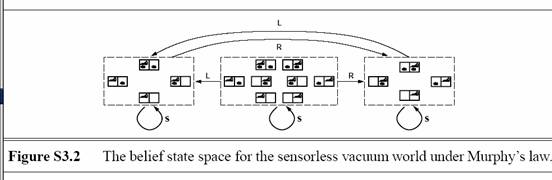
- (4 marks) Exercise 3.18
The belief
state space is shown in Figure S3.2. No solution is possible because no path
leads to a belief state all of whose elements satisfy the goal. If the problem
is fully observable, the agent reaches a goal state by executing a
sequence such that Suck is performed
only in a dirty square. This ensures deterministic behavior and every state is
obviously solvable.