This feed contains pages with tag "planet".
Context
- See hibernate-pocket, hibernate-pocket-2, hibernate-pocket-3, hibernate-pocket-4,hibernate-pocket-5, hibernate-pocket-6, hibernate-pocket-7, hibernate-pocket-8, hibernate-pocket-9 hibernate-pocket-10 hibernate-pocket-11 hibernate-pocket-12
Some progress upstream
Recently Sebastian Reichel at Collabora [1] has made a few related commits, apparently inspired in part by my kvetching on this blog.
Disconnecting and reconnecting PCI busses
At some point I noticed error message about the nvme device on resume. I then learned how to disconnect and reconnect PCI buses in Linux. I ended up with something like the following. At least the PCI management seems to work. I can manually disconnect all the PCI busses and rescan to connect them again on a running system. It presumably helps that I am not using the nvme device in this system.
set -x
echo platform > /sys/power/pm_test
echo reboot > /sys/power/disk
rmmod mt76x2u
sleep 2
echo 1 | tee /sys/bus/pci/devices/0003:30:00.0/remove
sleep 2
echo 1 | tee /sys/bus/pci/devices/0004:41:00.0/remove
sleep 2
echo 1 | tee /sys/bus/pci/devices/0004:40:00.0/remove
sleep 2
echo LSPCI:
lspci -t
sleep 2
echo disk > /sys/power/state
sleep 2
echo 1 | tee /sys/bus/pci/rescan
sleep 2
modprobe mt76x2u
Minimal changes to upstream
With the ongoing work at collabora I decided to try a minimal patch stack to get the pocket reform to boot. I added the following 3 commits (available from [3]).
09868a4f2eb (HEAD -> reform-patches) copy pocket-reform dts from reform-debian-packages
152e2ae8a193 pocket/panel: sleep fix v3
18f65da9681c add-multi-display-panel-driver
It does indeed boot and seems stable.
$ uname -a
Linux anthia 6.18.0-rc1+ #19 SMP Thu Oct 16 11:32:04 ADT 2025 aarch64 GNU/Linux
Running the hibernation script above I get no output from the lspci, but seemingly issues with PCI coming back from hibernate:
[ 424.645109] PM: hibernation: Allocated 361823 pages for snapshot
[ 424.647216] PM: hibernation: Allocated 1447292 kbytes in 3.23 seconds (448.07 MB/s)
[ 424.649321] Freezing remaining freezable tasks
[ 424.654767] Freezing remaining freezable tasks completed (elapsed 0.003 seconds)
[ 424.661070] rk_gmac-dwmac fe1b0000.ethernet end0: Link is Down
[ 424.740716] rockchip-dw-pcie a40c00000.pcie: Failed to receive PME_TO_Ack
[ 424.742041] PM: hibernation: hibernation debug: Waiting for 5 second(s).
[ 430.074757] pci 0004:40:00.0: [1d87:3588] type 01 class 0x060400 PCIe Root Port
F�F���&�Zn�[� watchdog: CPU4: Watchdog detected hard LOCKUP on cpu 5
[ 456.039004] Modules linked in: xt_CHECKSUM xt_tcpudp nft_chain_nat xt_MASQUERADE nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 nft_compat x_tables bridge stp llc nf_tables aes_neon_bs aes_neon_blk ccm dwmac_rk binfmt_misc mt76x2_common mt76x02_usb mt76_usb mt76x02_lib mt76 mac80211 rk805_pwrkey snd_soc_tlv320aic31xx snd_soc_simple_card reform2_lpc(OE) libarc4 rockchip_saradc industrialio_triggered_buffer kfifo_buf industrialio cfg80211 rockchip_thermal rockchip_rng hantro_vpu cdc_acm v4l2_vp9 v4l2_jpeg rockchip_rga rfkill snd_soc_rockchip_i2s_tdm videobuf2_dma_sg v4l2_h264 panthor snd_soc_audio_graph_card drm_gpuvm snd_soc_simple_card_utils drm_exec evdev joydev dm_mod nvme_fabrics efi_pstore configfs nfnetlink autofs4 ext4 crc16 mbcache jbd2 btrfs blake2b_generic xor xor_neon raid6_pq mali_dp snd_soc_meson_axg_toddr snd_soc_meson_axg_fifo snd_soc_meson_codec_glue panfrost drm_shmem_helper gpu_sched ao_cec_g12a meson_vdec(C) videobuf2_dma_contig videobuf2_memops v4l2_mem2mem videobuf2_v4l2 videodev
[ 456.039060] videobuf2_common mc dw_hdmi_i2s_audio meson_drm meson_canvas meson_dw_mipi_dsi meson_dw_hdmi mxsfb mux_mmio panel_edp imx_dcss ti_sn65dsi86 nwl_dsi mux_core pwm_imx27 hid_generic usbhid hid xhci_plat_hcd onboard_usb_dev xhci_hcd nvme nvme_core snd_soc_hdmi_codec snd_soc_core nvme_keyring nvme_auth hkdf snd_pcm_dmaengine snd_pcm snd_timer snd soundcore fan53555 rtc_pcf8523 micrel phy_package stmmac_platform stmmac pcs_xpcs rk808_regulator phylink sdhci_of_dwcmshc mdio_devres dw_mmc_rockchip of_mdio sdhci_pltfm phy_rockchip_usbdp fixed_phy dw_mmc_pltfm fwnode_mdio typec phy_rockchip_naneng_combphy phy_rockchip_samsung_hdptx pwm_rockchip sdhci dwc3 libphy dw_wdt dw_mmc ehci_platform rockchip_dfi mdio_bus cqhci ulpi ohci_platform ehci_hcd udc_core ohci_hcd rockchipdrm phy_rockchip_inno_usb2 usbcore dw_hdmi_qp analogix_dp dw_mipi_dsi cpufreq_dt dw_mipi_dsi2 i2c_rk3x usb_common drm_dp_aux_bus [last unloaded: mt76x2u]
[ 456.039111] Sending NMI from CPU 4 to CPUs 5:
[ 471.942262] page_pool_release_retry() stalled pool shutdown: id 9, 2 inflight 60 sec
[ 532.989611] page_pool_release_retry() stalled pool shutdown: id 9, 2 inflight 121 sec
This does look like some progress, probably thanks to Sebastien. Comparing with the logs in hibernate-pocket-12, the resume process is not bailing out complaining about PHY.
Attempt to reapply PCI reset patches
Following the procedure in hibernate-pocket-12, I attempted to
re-apply the pci reset patches [2]. In particular I followed the hints
output by b4.
Unfortunately there are too many conflicts now for me to sensibly resolve.
https://gitlab.collabora.com/hardware-enablement/rockchip-3588/linux.git#rockchip-devel
https://lore.kernel.org/all/20250715-pci-port-reset-v6-0-6f9cce94e7bb@oss.qualcomm.com/#r
https://salsa.debian.org/bremner/collabora-rockchip-3588#reform-patches
Context
- See hibernate-pocket, hibernate-pocket-2, hibernate-pocket-3, hibernate-pocket-4,hibernate-pocket-5, hibernate-pocket-6, hibernate-pocket-7, hibernate-pocket-8, hibernate-pocket-9 hibernate-pocket-10 hibernate-pocket-11
Update to latest rockchip-devel
For some reason I decided to try re-applying the PCI series. Good news: the pci series finally applies cleanly.
$ git fetch collabora && git switch -c tmp collabora # [1]
$ b4 am 20250715-pci-port-reset-v6-0-6f9cce94e7bb@oss.qualcomm.com
$ git switch reform-patches # [2]
$ git rebase -i tmp
- https://gitlab.collabora.com/hardware-enablement/rockchip-3588/linux.git#rockchip-devel
- https://salsa.debian.org/bremner/collabora-rockchip-3588#reform-patches
Rebuild the kernel
$ cp /boot/config-6.17.0-rc7+ .config
$ make olddefconfig
$ yes '' | make localmodconfig
$ make KBUILD_IMAGE=arch/arm64/boot/Image bindeb-pkg -j$(nproc)
try the hibernation test, again
Running the following test script
set -x
echo platform > /sys/power/pm_test
echo reboot > /sys/power/disk
sleep 2
rmmod mt76x2u
sleep 2
echo disk > /sys/power/state
sleep 2
modprobe mt76x2u
Initially there is some output like this
[ 151.752683] rockchip-dw-pcie a40c00000.pcie: Failed to receive PME_TO_Ack
[ 151.754035] PM: hibernation: hibernation debug: Waiting for 5 second(s).
[ 157.821584] rockchip-dw-pcie a40c00000.pcie: Phy link never came up
[ 157.822139] rockchip-dw-pcie a40c00000.pcie: fail to resume
[ 157.822636] rockchip-dw-pcie a40c00000.pcie: PM: dpm_run_callback(): genpd_restore_noirq returns -110
[ 157.823442] rockchip-dw-pcie a40c00000.pcie: PM: failed to restore noirq: error -110
A small amount of detective work suggests that a40c00000.pcie corresponds to the
first PCI bridge on the rk3588 SOC.
$ ls -l /sys/bus/pci/devices
total 0
lrwxrwxrwx 1 root root 0 Sep 23 10:32 0003:30:00.0 -> ../../../devices/platform/a40c00000.pcie/pci0003:30/0003:30:00.0
lrwxrwxrwx 1 root root 0 Sep 23 10:32 0004:40:00.0 -> ../../../devices/platform/a41000000.pcie/pci0004:40/0004:40:00.0
lrwxrwxrwx 1 root root 0 Sep 23 10:32 0004:41:00.0 -> ../../../devices/platform/a41000000.pcie/pci0004:40/0004:40:00.0/0004:41:00.0
Then after a pause,
[ 1032.039237] watchdog: CPU5: Watchdog detected hard LOCKUP on cpu 6
[ 1032.039778] Modules linked in: xt_CHECKSUM xt_tcpudp nft_chain_nat xt_MASQUERADE nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 nft_compat x_tables bridge stp llc nf_tables aes_neon_bs aes_neon_blk ccm dwmac_rk binfmt_misc mt76x2_common mt76x02_usb mt76_usb mt76x02_lib mt76 rk805_pwrkey snd_soc_tlv320aic31xx snd_soc_simple_card mac80211 rockchip_saradc reform2_lpc(OE) industrialio_triggered_buffer libarc4 kfifo_buf cfg80211 industrialio rockchip_thermal rockchip_rng cdc_acm rfkill snd_soc_rockchip_i2s_tdm hantro_vpu rockchip_rga panthor v4l2_vp9 v4l2_jpeg snd_soc_audio_graph_card videobuf2_dma_sg v4l2_h264 drm_gpuvm snd_soc_simple_card_utils drm_exec evdev joydev dm_mod nvme_fabrics efi_pstore configfs nfnetlink autofs4 ext4 crc16 mbcache jbd2 btrfs blake2b_generic xor xor_neon raid6_pq mali_dp snd_soc_meson_axg_toddr snd_soc_meson_axg_fifo snd_soc_meson_codec_glue panfrost drm_shmem_helper gpu_sched ao_cec_g12a meson_vdec(C) videobuf2_dma_contig videobuf2_memops v4l2_mem2mem videobuf2_v4l2 videodev
[ 1032.039834] videobuf2_common mc dw_hdmi_i2s_audio meson_drm meson_canvas meson_dw_mipi_dsi meson_dw_hdmi mxsfb mux_mmio panel_edp imx_dcss ti_sn65dsi86 nwl_dsi mux_core pwm_imx27 hid_generic usbhid hid onboard_usb_dev nvme nvme_core nvme_keyring nvme_auth snd_soc_hdmi_codec snd_soc_core xhci_plat_hcd xhci_hcd snd_pcm_dmaengine snd_pcm snd_timer snd soundcore rtc_pcf8523 fan53555 micrel phy_package stmmac_platform stmmac pcs_xpcs phylink mdio_devres rk808_regulator of_mdio sdhci_of_dwcmshc fixed_phy sdhci_pltfm fwnode_mdio libphy sdhci phy_rockchip_usbdp dw_mmc_rockchip dw_mmc_pltfm typec phy_rockchip_naneng_combphy pwm_rockchip dw_wdt phy_rockchip_samsung_hdptx dwc3 cqhci dw_mmc mdio_bus rockchip_dfi ehci_platform rockchipdrm ulpi ehci_hcd dw_hdmi_qp ohci_platform udc_core ohci_hcd analogix_dp dw_mipi_dsi i2c_rk3x cpufreq_dt usbcore phy_rockchip_inno_usb2 dw_mipi_dsi2 drm_dp_aux_bus usb_common [last unloaded: mt76x2u]
[ 1032.039886] Sending NMI from CPU 5 to CPUs 6:
Context
- See hibernate-pocket, hibernate-pocket-2, hibernate-pocket-3, hibernate-pocket-4,hibernate-pocket-5, hibernate-pocket-6, hibernate-pocket-7, hibernate-pocket-8, hibernate-pocket-9 hibernate-pocket-10
Update to latest rockchip-devel
- rebase reform-patches on top of collabora/rockchip-devel
- pci reset series has new conflicts
- try dropping from rebase and re-applying
$ b4 am 20250715-pci-port-reset-v6-0-6f9cce94e7bb@oss.qualcomm.com
# follow hint from b4
$ git checkout -b v6_20250715_manivannan_sadhasivam_oss_qualcomm_com 19272b37aa4f83ca52bdf9c16d5d81bdd1354494
$ git am ./v6_20250715_manivannan_sadhasivam_pci_add_support_for_resetting_the_root_ports_in_a_platform_specifi.mbx
$ git rebase -i collabora/rockchip-devel
- conflict in pcie-qcom.c: take new version
conflict in pcie-dw-rockchip.c resolved as in hibernate-pocket-8
rebase reform patches on top of pci reset, instead of vice versa.
rebuild as discussed in hibernate-pocket-8
$ cp /boot/config-6.16.0-rc7+ .config
$ make olddefconfig
# this generates a message about "reform2_lpc config not found!!"
# and "rockchip_vdec2 config not found!!"
# hopefully this is ok
$ yes '' | make localmodconfig
$ make KBUILD_IMAGE=arch/arm64/boot/Image bindeb-pkg -j$(nproc)
Introducing git-remote-notmuch
Based on an idea and ruby implementation by Felipe Contreras, I have been developing a git remote helper for notmuch. I will soon post an updated version of the patchset to the notmuch mailing list (I wanted to refer to this post in my email). In this blog post I'll outline my experiments with using that tool, along with git-annex to store (and sync) a moderate sized email store along with its notmuch metadata.
WARNING
The rest of this post describes some relatively complex operations
using (at best) alpha level software (namely
git-remote-notmuch). git-annex is good at not losing your files,
but git-remote-notmuch can (and did several times during debugging)
wipe out your notmuch database. If you have a backup (e.g. made with
notmuch-dump), this is much less annoying, and in particular you can
decide to walk away from this whole experiment and restore your
database.
Why git-annex?
I currently have about 31GiB of email, spread across more than 830,000
files. I want to maintain the ability to search and read my email
offline, so I need to maintain a copy on several workstations and at
least one server (which is backed up explicitly). I am somewhat
commited to maintaining synchronization of tags to git since that is
how the notmuch bug tracker works. Commiting the email files to
git seems a bit wasteful: by design notmuch does not modify email
files, and even with compression, the extra copy adds a fair amount of
overhead (in my case, 17G of git objects, about 57% overhead). It is
also notoriously difficult to completely delete files from a git
repository. git-annex offers potential mitigation for these two
issues, at the cost of a somewhat more complex mental model. The main
idea is that instead of committing every version of a file to the git
repository, git-annex tracks the filename and metadata, with the
file content being stored in a key-value store outside
git. Conceptually this is similar to git-lfs. From our current
point, the important point is that instead of a second (compressed)
copy of the file, we store one copy, along with a symlink and a couple
of directory entries.
What to annex
For sufficiently small files, the overhead of a symlink and couple of
directory entries is greater than the cost of a compressed second
copy. When this happens depends on several variables, and will
probably depend on the file content in a particular collection of
email. I did a few trials of different settings for annex.largefiles
to come to a threshold of largerthan=32k 1. For the curious, my
experimental results are below. One potentially surprising aspect is
that annexing even a small fraction of the (largest) files yields a
big drop in storage overhead.
| Threshold | fraction annexed | overhead |
|---|---|---|
| 0 | 100% | 30% |
| 8k | 29% | 13% |
| 16k | 12% | 9.4% |
| 32k | 7% | 8.9% |
| 48k | 6% | 8.9% |
| 100k | 3% | 9.1% |
| 256k | 2% | 11% |
| ∞ (git) | 0 % | 57% |
In the end I chose to err on the side of annexing more files (for the flexibility of deletion) rather than potentially faster operations with fewer annexed files at the same level of overhead.
Summarizing the configuration settings for git-annex (some of these
are actually defaults, but not in my environment).
$ git config annex.largefiles largerthan=32k
$ git config annex.dotfiles true
$ git config annex.synccontent true
Delivering mail
To get new mail, I do something like
# compute a date based folder under $HOME/Maildir
$ dest = $(folder)
# deliver mail to ${dest} (somehow).
$ notmuch new
$ git -C $HOME/Maildir add ${folder}
$ git -C $HOME/Maildir diff-index --quiet HEAD ${folder} || git -C $HOME/Maildir commit -m 'mail delivery'
The call to diff-index is just an optimization for the case when
nothing was delivered. The default configuration of git-annex will
automagically annex any files larger than my threshold. At this point
the git-annex repo knows nothing about tags.
There is some git configuration that can speed up the "git add" above, namely
$ git config core.untrackedCache true
$ git config core.fsmonitor true
See git-status(1) under "UNTRACKED FILES AND PERFORMANCE"
Defining notmuch as a git remote
Assuming git-remote-notmuch is somewhere in your path, you can define
a remote to connect to the default notmuch database.
$ git remote add database notmuch::
$ git fetch database
$ git merge --allow-unrelated database
The --allow-unrelated should be needed only the first time.
In my case the many small files used to represent the tags (one per message), use a noticeable amount of disk space (in my case about the same amount of space as the xapian database).
Once you start merging from the database to the git repo, you will
likely have some conflicts, and most conflict resolution tools leave
junk lying around. I added the following .gitignore file to the top
level of the repo
*.orig
*~
This prevents our cavalier use of git add from adding these files to
our git history (and prevents pushing random junk to the notmuch
database.
To push the tags from git to notmuch, you can run
$ git push database master
You might need to run notmuch new first, so that the database knows
about all of the messages (currently git-remote-notmuch can't index
files, only update metadata).
git annex sync should work with the new remote, but pushing back
will be very slow 2. I disable automatic pushing as follows
$ git config remote.database.annex-push false
Unsticking the database remote
If you are debugging git-remote-notmuch, or just unlucky, you may
end up in a sitation where git thinks the database is ahead of your
git remote. You can delete the database remote (and associated stuff)
and re-create it. Although I cannot promise this will never cause
problems (because, computers), it will not modify your local copy of
the tags in the git repo, nor modify your notmuch database.
$ git remote rm database
$ git update-ref -d notmuch/master
$ rm -r .git/notmuch
Fine tuning notmuch config
In order to avoid dealing with file renames, I have
notmuch config maildir.synchronize_flags falseI have added the following to
new.ignore:.git;_notmuch_metadata;.gitignore
Context
- See hibernate-pocket, hibernate-pocket-2, hibernate-pocket-3, hibernate-pocket-4,hibernate-pocket-5, hibernate-pocket-6, hibernate-pocket-7, hibernate-pocket-8, hibernate-pocket-9
Finally applying the pci reset series.
$ b4 am 20250715-pci-port-reset-v6-0-6f9cce94e7bb@oss.qualcomm.com
$ git am -3 v6_20250715_manivannan_sadhasivam_pci_add_support_for_resetting_the_root_ports_in_a_platform_specifi.mbx
There is quite a scary looking conflict between the last patch in the
series and
https://lore.kernel.org/r/1744940759-23823-1-git-send-email-shawn.lin@rock-chips.com
which is now upstream (collabora) in rockchip-devel. I resolved
the second basically by taking both, as it seemed like two independent sets of
additions to the same parts of the file. The first it looks like Shawn's commit referenced above should prevail.
If anyone is curious about the (possibly incorrectly) rebased patches, they are at
https://salsa.debian.org/bremner/collabora-rockchip-3588
(
reform-patchesis the default, and relevant branch).
testing
- The new (6.16~rc7+) kernel boots
It successfully reboots
devices test passes, although the UBSAN warning / error is still there
174.559032] UBSAN: array-index-out-of-bounds in net/mac80211/rc80211_minstrel_ht.c:409:33
[ 174.559830] index 15 is out of range for type 'minstrel_rate_stats [10]'
[ 174.560462] CPU: 7 UID: 0 PID: 213 Comm: kworker/u32:10 Tainted: G WC OE 6.16.0-rc7+ #6 NONE
[ 174.560470] Tainted: [W]=WARN, [C]=CRAP, [O]=OOT_MODULE, [E]=UNSIGNED_MODULE
[ 174.560472] Hardware name: MNT Pocket Reform with RCORE RK3588 Module (DT)
[ 174.560474] Workqueue: mt76 mt76u_tx_status_data [mt76_usb]
[ 174.560489] Call trace:
[ 174.560491] show_stack+0x34/0x98 (C)
[ 174.560501] dump_stack_lvl+0x60/0x80
[ 174.560508] dump_stack+0x18/0x24
[ 174.560514] ubsan_epilogue+0x10/0x48
[ 174.560520] __ubsan_handle_out_of_bounds+0xa0/0xd0
[ 174.560526] minstrel_ht_tx_status+0x890/0xc68 [mac80211]
[ 174.560633] rate_control_tx_status+0xbc/0x180 [mac80211]
[ 174.560730] ieee80211_tx_status_ext+0x1d8/0x9a0 [mac80211]
[ 174.560822] mt76_tx_status_unlock+0x188/0x2a0 [mt76]
[ 174.560844] mt76x02_send_tx_status+0x130/0x4a0 [mt76x02_lib]
[ 174.560860] mt76x02_tx_status_data+0x64/0xa8 [mt76x02_lib]
[ 174.560872] mt76u_tx_status_data+0x84/0x120 [mt76_usb]
[ 174.560879] process_one_work+0x178/0x3c8
[ 174.560885] worker_thread+0x208/0x400
[ 174.560890] kthread+0x120/0x220
[ 174.560894] ret_from_fork+0x10/0x20
[ 174.560898] ---[ end trace ]---
- "platform" test still fails with
[ 88.484072] rk_gmac-dwmac fe1b0000.ethernet end0: Link is Down
[ 88.597026] rockchip-dw-pcie a40c00000.pcie: Failed to receive PME_TO_Ack
[ 88.598523] PM: hibernation: hibernation debug: Waiting for 5 second(s).
[ 94.667723] rockchip-dw-pcie a40c00000.pcie: Phy link never came up
[ 94.668281] rockchip-dw-pcie a40c00000.pcie: fail to resume
[ 94.668783] rockchip-dw-pcie a40c00000.pcie: PM: dpm_run_callback(): genpd_restore_noirq returns -110
[ 94.669594] rockchip-dw-pcie a40c00000.pcie: PM: failed to restore noirq: error -110
[ 120.035426] watchdog: CPU4: Watchdog detected hard LOCKUP on cpu 5
[ 120.035978] Modules linked in: xt_CHECKSUM xt_tcpudp nft_chain_nat xt_MASQUERADE nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 nft_compat bridge stp llc nf_tables aes_neon_bs aes_neon_blk ccm snd_seq_dummy snd_hrtimer snd_seq snd_seq_device dwmac_rk binfmt_misc mt76x2_common mt76x02_usb mt76_usb mt76x02_lib mt76 mac80211 libarc4 snd_soc_simple_card rockchip_saradc industrialio_triggered_buffer cfg80211 snd_soc_tlv320aic31xx rk805_pwrkey kfifo_buf reform2_lpc(OE) industrialio rockchip_thermal rfkill rockchip_rng hantro_vpu cdc_acm rockchip_rga v4l2_vp9 snd_soc_rockchip_i2s_tdm rockchip_vdec2 panthor videobuf2_dma_sg v4l2_jpeg drm_gpuvm v4l2_h264 drm_exec snd_soc_audio_graph_card snd_soc_simple_card_utils joydev evdev dm_mod nvme_fabrics efi_pstore configfs nfnetlink ip_tables x_tables autofs4 ext4 crc16 mbcache jbd2 btrfs blake2b_generic xor xor_neon raid6_pq mali_dp snd_soc_meson_axg_toddr snd_soc_meson_axg_fifo snd_soc_meson_codec_glue panfrost drm_shmem_helper gpu_sched ao_cec_g12a meson_vdec(C)
[ 120.036066] videobuf2_dma_contig hid_generic videobuf2_memops v4l2_mem2mem videobuf2_v4l2 videodev videobuf2_common mc dw_hdmi_i2s_audio meson_drm meson_canvas meson_dw_mipi_dsi meson_dw_hdmi usbhid hid mxsfb mux_mmio panel_edp imx_dcss ti_sn65dsi86 nwl_dsi mux_core pwm_imx27 xhci_plat_hcd xhci_hcd onboard_usb_dev snd_soc_hdmi_codec snd_soc_core micrel snd_pcm_dmaengine nvme snd_pcm nvme_core snd_timer snd nvme_keyring nvme_auth soundcore stmmac_platform stmmac pcs_xpcs phylink mdio_devres of_mdio sdhci_of_dwcmshc fixed_phy sdhci_pltfm phy_rockchip_usbdp dw_mmc_rockchip fwnode_mdio ehci_platform typec phy_rockchip_samsung_hdptx phy_rockchip_naneng_combphy rk808_regulator pwm_rockchip dwc3 dw_wdt libphy fan53555 ohci_platform sdhci ehci_hcd ulpi rtc_pcf8523 dw_mmc_pltfm udc_core ohci_hcd dw_mmc cqhci mdio_bus rockchip_dfi rockchipdrm dw_hdmi_qp analogix_dp i2c_rk3x usbcore phy_rockchip_inno_usb2 dw_mipi_dsi dw_mipi_dsi2 usb_common cpufreq_dt drm_dp_aux_bus [last unloaded: mt76x2u]
[ 120.036150] Sending NMI from CPU 4 to CPUs 5:
- The results are similar if I uncomment the unloading of the dwc3 module
set -x
echo platform > /sys/power/pm_test
echo reboot > /sys/power/disk
sleep 2
rmmod mt76x2u
sleep 2
#rmmod dwc3
#sleep 2
echo disk > /sys/power/state
sleep 2
#modprobe dwc3
#sleep 2
modprobe mt76x2u
Unsurprisingly, if I try an actual resume (instead of a "platform" test), I get the same messages about "Phy link never came up" and the system needs a hard reboot after trying to resume.
Barring inspiration, my next move will be to report my lack of success to the appropriate kernel mailing list(s).
Context
- See hibernate-pocket, hibernate-pocket-2, hibernate-pocket-3, hibernate-pocket-4,hibernate-pocket-5, hibernate-pocket-6, hibernate-pocket-7, hibernate-pocket-8
Sidequest: Install u-boot-menu
Don't be like me and reboot without configuring u-boot-menu. Although the defaults make sense for most people, in my case I lost access to the serial console (because that custom config needed to be re-done), and the default delay was not enough to choose a backup kernel. In consfigurator notation:
(on-change
(file:has-content "/etc/u-boot-menu/conf.d/reform.conf"
'("U_BOOT_TIMEOUT=50"
"U_BOOT_PARAMETERS=\"ro no_console_suspend cryptomgr.notests \\${bootargs} console=ttyS2,1500000 keep_bootcon console=tty1\""))
(cmd:single "u-boot-update"))
The panel, alive.
Thanks to a hint from
joschc(and a bit of luck) I realized the
issue I filed was nonsense. Yay?The panel driver is not added by the rk3588 patches (since the build process applies all the patches, this is not a problem for building from
reform-debian-packages).After applying the two patches in
reform-debian-packages/linux/patches6.15/imx8mp-mnt-pocket-reform/pocket-panel, the patched 6.16 kernel boots, and seems to work, including the panel.The updated source is on branch
reform-patchesathttps://salsa.debian.org/bremner/collabora-rockchip-3588
Unsurprisingly hibernate is not working out of the box with 6.16. My next mission is to apply the recommended pci-reset patches on top of 6.16.
Context
- See hibernate-pocket, hibernate-pocket-2, hibernate-pocket-3, hibernate-pocket-4, hibernate-pocket-5, hibernate-pocket-6, hibernate-pocket-7
Sidequest: Fix patches continued
1001-pci_dw_rockchip_enable_l0s_capability.patch doesn't apply cleanly either
b4 am 1744594051-209255-1-git-send-email-shawn.lin@rock-chips.com
This one has a usable blob index
21dc99cgit log --raw --all --find-object=21dc99cfinds the patch already applied as198e69cc4150aba1e7af740a2111ace6a267779e1002-v2-media_verisilicon_fix_av1_decoder_clock_frequency.patchapplies cleanly
Build kernel with backported patches
Back following the upstream bisect instructions from reform-debian-packages/README.md
$ apt-get install git gpg gpgv build-essential bc rsync kmod cpio bison flex libelf-dev libssl-dev debhelper libdw-dev
$ cp /boot/config-6.15.4-mnt-reform-arm64 .config
$ make olddefconfig
$ yes '' | make localmodconfig
$ make KBUILD_IMAGE=arch/arm64/boot/Image bindeb-pkg -j$(nproc)
One thing not documented there is that you need the pocket-reform dtb as well.
Copy that file from reform-debian-packages, and update the relevant Makefile.
diff --git a/arch/arm64/boot/dts/rockchip/Makefile b/arch/arm64/boot/dts/rockchip/Makefile
index 26533be1dd86..83ef850cd113 100644
--- a/arch/arm64/boot/dts/rockchip/Makefile
+++ b/arch/arm64/boot/dts/rockchip/Makefile
@@ -163,6 +163,7 @@ dtb-$(CONFIG_ARCH_ROCKCHIP) += rk3588-h96-max-v58.dtb
dtb-$(CONFIG_ARCH_ROCKCHIP) += rk3588-jaguar.dtb
dtb-$(CONFIG_ARCH_ROCKCHIP) += rk3588-jaguar-pre-ict-tester.dtbo
dtb-$(CONFIG_ARCH_ROCKCHIP) += rk3588-mnt-reform2.dtb
+dtb-$(CONFIG_ARCH_ROCKCHIP) += rk3588-mnt-pocket-reform.dtb
dtb-$(CONFIG_ARCH_ROCKCHIP) += rk3588-nanopc-t6.dtb
dtb-$(CONFIG_ARCH_ROCKCHIP) += rk3588-nanopc-t6-lts.dtb
dtb-$(CONFIG_ARCH_ROCKCHIP) += rk3588-ok3588-c.dtb
diff --git a/arch/arm64/boot/dts/rockchip/rk3588-mnt-pocket-reform.dts b/arch/arm64/boot/dts/rockchip/rk3588-mnt-pocket-reform.dts
new file mode 100644
index 000000000000..81533cedc200
- With these changes I can boot in to 6.16~rc6, and log in the serial console, but the LCD display seems blank (but with some backlight power). That is probably related to the following warnings from device tree compilation
DTC arch/arm64/boot/dts/rockchip/rk3588-mnt-pocket-reform.dtb
arch/arm64/boot/dts/rockchip/rk3588-mnt-pocket-reform.dts:1020.3-13: Warning (reg_format): /dsi@fde30000/panel:reg: property has invalid length (4 bytes) (#address-cells == 2, #size-cells == 1)
arch/arm64/boot/dts/rockchip/rk3588-mnt-pocket-reform.dtb: Warning (pci_device_reg): Failed prerequisite 'reg_format'
arch/arm64/boot/dts/rockchip/rk3588-mnt-pocket-reform.dtb: Warning (pci_device_bus_num): Failed prerequisite 'reg_format'
arch/arm64/boot/dts/rockchip/rk3588-mnt-pocket-reform.dtb: Warning (i2c_bus_reg): Failed prerequisite 'reg_format'
arch/arm64/boot/dts/rockchip/rk3588-mnt-pocket-reform.dtb: Warning (spi_bus_reg): Failed prerequisite 'reg_format'
arch/arm64/boot/dts/rockchip/rk3588-mnt-pocket-reform.dts:1018.8-1033.4: Warning (avoid_default_addr_size): /dsi@fde30000/panel: Relying on default #address-cells value
arch/arm64/boot/dts/rockchip/rk3588-mnt-pocket-reform.dts:1018.8-1033.4: Warning (avoid_default_addr_size): /dsi@fde30000/panel: Relying on default #size-cells value
The current source is on
https://salsa.debian.org/bremner/collabora-rockchip-3588
The branch "reform-patches" is subject to rebase (and may make your computer explode).
For now I'm blocked on the panel, I suspect the dts file needs an update.
Context
- See hibernate-pocket, hibernate-pocket-2, hibernate-pocket-3, hibernate-pocket-4, hibernate-pocket-5, hibernate-pocket-6
Building upstream-ish kernel
- Roughly following the "bisecting upstream linux" section of
reform-debian-packages/README.md
$ git clone https://gitlab.collabora.com/hardware-enablement/rockchip-3588/linux.git collabora
$ cd collabora && git git switch -c rockchip-devel origin/rockchip-devel
The next step is to apply the the non-collabora patches from
reform-debian-packages/linux/patches6.15/rk3588-mnt-reform2Unfortunately these are missing the proper metadata to work with git-am
Sidequest: Fix patches
1000-v3-pci_dw_rockchip_add_system_pm_support.patch doesn't apply, even with added metadata. Start again upstream.
Thanks to
joshcfor the suggestion of theb4tool.b4 am 1744940759-23823-1-git-send-email-shawn.lin@rock-chips.comThis creates a
.mbxfile ready for git am (roughly equivalent to fetching the/rawversion from lore, with some extra checks).Brute force finding a base for the patch:
git rev-list --no-merges --since 2025-01-01 refs/heads/rockchip-devel | \
while read ref
do
echo trying $ref
git checkout $ref
git apply --check v3_20250418_shawn_lin_pci_dw_rockchip_add_system_pm_support.mbx && echo SUCCESS && break
done
- 122 steps later this yields 9dff55ebaef7 (bisect would be better if we knew a "good" commit).
$ git branch -D tmp ; git switch -c tmp 9dff55ebaef7
$ git am v3_20250418_shawn_lin_pci_dw_rockchip_add_system_pm_support.mbx
$ git rebase -i rockchip-devel
This fails with 3 conflicts. The first is easy, as the one non-comment
line just moves around. The other two involve a new function
rockchip_pcie_unmask_dll_indicator used to reduce code duplication, and in all
3 cases I just took the version of the code from Shawn's patch.
EDIT This rebase turns out to miss (at least) changes in the names
of the PCI* constants. By amusing(?) coincidence, as I was
discovering that, the patch was being rebased by someone more
competent at collabora, and is now in the rockchip-devel branch.
Context
- See hibernate-pocket, hibernate-pocket-2, hibernate-pocket-3, hibernate-pocket-4, hibernate-pocket-5
Another kernel patch?
Confused about prerequisites, I wrote
A reply from Niklas Cassel suggested I look at
https://lore.kernel.org/linux-pci/1744940759-23823-1-git-send-email-shawn.lin@rock-chips.com/
EDIT It turns out that this patch is already shipped as part of the mnt research kernel. It will need rebasing for 6.16.x.
Applying the prerequisites
Niklas also point me to
https://lore.kernel.org/linux-pci/20250508-pcie-reset-slot-v4-0-7050093e2b50@linaro.org/
Since the new patch doesn't apply to linux master either, I guess I need to apply that series. But part of it is already applied, fun.
I'm not claiming this is the best way...
# index 31090770fffcc94e15 from the first patch in the series
$ git log --raw --all --find-object=31090770fffcc94e15
# The applied version of the first patch is `b06d125e6280603a34d9064cd9c12748ca2edb04`
$ git switch -c base b06d125e6280603a34d9064cd9c12748ca2edb04^
$ mbox-extract-patch < ~/Downloads/PATCH-v4-1-5-PCI-ERR-Remove-misleading-TODO-regarding-kernel-panic.mbox | git am
$ git rebase -i master # two applied patches skipped
$ git switch master && git merge base
mbox-extract-patchis from package mailscripts.git am -3 ~/tmp/PATCH-v3-PCI-dw-rockchip-Add-support-for-slot-reset-on-link-down-event.txtCurrently can't get the "Add system PM support" patch to apply, will test the others first.
Except that a test build tells me I need to rebase all of my patches against 6.15.x, rather the the current 6.16~rcX
Context
A Kernel Patch
- The follow patch looks potentially relevant:
https://patchwork.kernel.org/project/linux-rockchip/patch/20250509-b4-pci_dwc_reset_support-v3-1-37e96b4692e7@wdc.com/
git clone https://github.com/torvalds/linux.git (Is there a better place? kernel.org is pretty opaque)
are the pre-reqs in mnt kernel? The patch header contains
base-commit: 08733088b566b58283f0f12fb73f5db6a9a9de30
change-id: 20250430-b4-pci_dwc_reset_support-d720dbafb7ea
prerequisite-change-id: 20250404-pcie-reset-slot-730bfa71a202:v4
prerequisite-patch-id: 2dad85eb26838d89569b12c19d70f392fa592667
prerequisite-patch-id: 6238a682bd8e9476e5911b7a59263c3fc618d63e
prerequisite-patch-id: 37cab00bc255a62b1e8396a48a3afba5e1751abd
prerequisite-patch-id: ff711f65cf9926374646b76cd38bdd823d576764
prerequisite-patch-id: 1654cca919d024b9a9190b28e90f722975c797e8
- First check and see what is upstream. I had to remember how to use
git-patch-idand also how to split a long regex disjunction into multiple lines.
git log --patch --no-merges v6.13.. | \
git patch-id --stable | \
grep -F -e 2dad85eb26838d89569b12c19d70f392fa592667 \
-e 6238a682bd8e9476e5911b7a59263c3fc618d63e \
-e 37cab00bc255a62b1e8396a48a3afba5e1751abd \
-e ff711f65cf9926374646b76cd38bdd823d576764 \
-e 1654cca919d024b9a9190b28e90f722975c797e8
yields
37cab00bc255a62b1e8396a48a3afba5e1751abd d1c696dba120624256ab335ab8247f535b872309
2dad85eb26838d89569b12c19d70f392fa592667 b06d125e6280603a34d9064cd9c12748ca2edb04
The two commits that are actually found, are only in tag 'v6.16~rc1'
- The discussion on LKML mentions
pci/slot-reset. Where does that branch live?
git remote add pci https://git.kernel.org/pub/scm/linux/kernel/git/pci/pci.git
git fetch pci
git for-each-ref refs/remotes/pci --format "%(refname)" | \
while read branch
do
echo "checking $branch"
git log --patch --no-merges --since 2025-01-01 $branch | \
git patch-id --stable | \
grep -F -e 2dad85eb26838d89569b12c19d70f392fa592667 \
-e 6238a682bd8e9476e5911b7a59263c3fc618d63e \
-e 37cab00bc255a62b1e8396a48a3afba5e1751abd \
-e ff711f65cf9926374646b76cd38bdd823d576764 \
-e 1654cca919d024b9a9190b28e90f722975c797e8
done
This did not find any more commits, but I did learn how to use
git-for-each-ref, so I guess not a total loss.
Context
Log from (failed) platform test
After some fun I got the serial console working and re-ran the platform test.
After a bit of reading the serial console, I realized that rmmod dwc3 was causing
more problems than it solved, in particularly reliable hard lockup on one of the CPUs.
My revised test script is
set -x
echo platform > /sys/power/pm_test
echo reboot > /sys/power/disk
sleep 2
rmmod mt76x2u
sleep 2
echo disk > /sys/power/state
sleep 2
modprobe mt76x2u
The current problem seems to be pcie not resuming properly.
[ 65.306842] usbcore: deregistering interface driver mt76x2u
[ 65.343606] wlx000a5205eb2d: deauthenticating from 20:05:b7:00:2d:89 by local choice (Reason: 3=DEAUTH_LEAVING)
[ 67.995239] PM: hibernation: hibernation entry
[ 68.048103] Filesystems sync: 0.022 seconds
[ 68.049005] Freezing user space processes
[ 68.051075] Freezing user space processes completed (elapsed 0.001 seconds)
[ 68.051760] OOM killer disabled.
[ 68.052597] PM: hibernation: Basic memory bitmaps created
[ 68.053108] PM: hibernation: Preallocating image memory
[ 69.719040] PM: hibernation: Allocated 366708 pages for snapshot
[ 69.719650] PM: hibernation: Allocated 1466832 kbytes in 1.66 seconds (883.63 MB/s)
[ 69.720370] Freezing remaining freezable tasks
[ 69.723558] Freezing remaining freezable tasks completed (elapsed 0.002 seconds)
[ 69.728002] rk_gmac-dwmac fe1b0000.ethernet end0: Link is Down
[ 69.992324] rockchip-dw-pcie a40c00000.pcie: Failed to receive PME_TO_Ack
[ 69.993405] PM: hibernation: debug: Waiting for 5 seconds.
[ 76.059484] rockchip-dw-pcie a40c00000.pcie: Phy link never came up
[ 76.060043] rockchip-dw-pcie a40c00000.pcie: fail to resume
[ 76.060546] rockchip-dw-pcie a40c00000.pcie: PM: dpm_run_callback(): genpd_restore_noirq returns -110
[ 76.061363] rockchip-dw-pcie a40c00000.pcie: PM: failed to restore noirq: error -110
Context
Serial console hardware
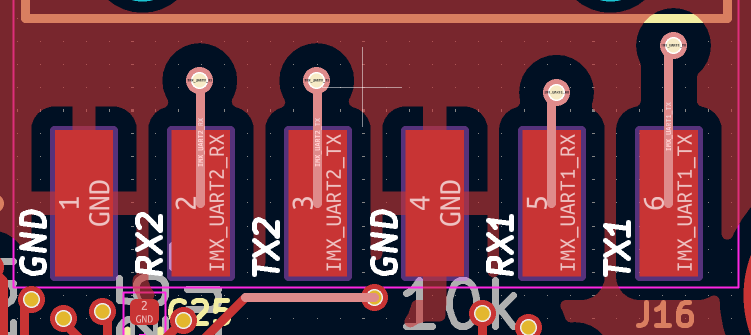
- Manual is unclear about name of connector (J16 in schematics, J17 in manual).
- Also numbering of pins is not given afaict.
- Clone https://source.mnt.re/reform/pocket-reform.git
- Look at pocket-reform-motherboard.kicad_pcb
- From the PCB I can confirm J16 and pins numbered left (sysctl) to right.
- attach "dtech" prolific PL2303 based serial to usb cable per serial console section of PR manual
- lsusb shows
ID 067b:23a3 Prolific Technology, Inc. ATEN Serial Bridge - install
tio - add my user to group
dialout newgrp dialout- tio /dev/ttyUSB0 -b 1500000
- A closer look at the PCB in kicad makes me realize the pin labels in the manual are wrong. 4 = GND, 5 =
UART1_RX, 6=UART1_TX. With that change I have U-boot output on boot.
Serial console software
With some help from minute on ircs://irc.libera.chat:6697/#mnt-reform, I got
the kernel boot arguments right to have not just u-boot output but linux kernel output on the serial console. In consfigurator notation
(on-change
(file:has-content "/etc/flash-kernel/ubootenv.d/00reform2_serial_console"
"setenv bootargs \"${bootargs} console=ttyS2,1500000 keep_bootcon\"")
(cmd:single "flash-kernel"))
The filename should sort before "00reform2_ubootenv" so that the existing "console=tty1" still ends up at the end.
Context
- See hibernate-pocket
Testing continued
- following a suggestion of
gordon1, unload the mediatek module first. The following seems to work, either from the console or under sway
echo devices > /sys/power/pm_test
echo reboot > /sys/power/disk
rmmod mt76x2u
echo disk > /sys/power/state
modprobe mt76x2u
- It even works via ssh (on wired ethernet) if you are a bit more patient for it to come back.
- replacing "reboot" with "shutdown" doesn't seem to affect test mode.
- replacing "devices" with "platform" (or "processors") leads to unhappiness.
- under sway, the screen goes blank, and it does not resume
- same on console
Configuration
script: https://docs.kernel.org/power/basic-pm-debugging.html
kernel is 6.15.4-1~exp1+reform20250628T170930Z
State of things
normal reboot works
Either from the console, or from sway, the intial test of reboot mode hibernate fails. In both cases it looks very similar to halting.
- the screen is dark (but not completely black)
- the keyboard is still illuminated
- the system-controller still seems to work, althought I need to power off before I can power on again, and any "hibernation state" seems lost.
Running tests
- this is 1a from above
- freezer test passes
- devices test from console
- console comes back (including input)
- networking (both wired and wifi) seems wedged.
- console is full of messages from mt76x2u about vendor request 06 and 07 failing. This seems related to https://github.com/morrownr/7612u/issues/17
- at some point the console becomes non-responsive, except for the aforementioned messages from the wifi module.
- devices test under sway
- display comes back
- keyboard/mouse seem disconnected
- network down / disconnected?
My web pages are (still) in ikiwiki, but lately I have started authoring things like assignments and lectures in org-mode so that I can have some literate programming facilities. There is is org-mode export built-in, but it just exports source blocks as examples (i.e. unhighlighted verbatim). I added a custom exporter to mark up source blocks in a way ikiwiki can understand. Luckily this is not too hard the second time.
(with-eval-after-load "ox-md"
(org-export-define-derived-backend 'ik 'md
:translate-alist '((src-block . ik-src-block))
:menu-entry '(?m 1 ((?i "ikiwiki" ik-export-to-ikiwiki)))))
(defun ik-normalize-language (str)
(cond
((string-equal str "plait") "racket")
((string-equal str "smol") "racket")
(t str)))
(defun ik-src-block (src-block contents info)
"Transcode a SRC-BLOCK element from Org to beamer
CONTENTS is nil. INFO is a plist used as a communication
channel."
(let* ((body (org-element-property :value src-block))
(lang (ik-normalize-language (org-element-property :language src-block))))
(format "[[!format <span class="error">Error: unsupported page format %s</span>]]" lang body)))
(defun ik-export-to-ikiwiki
(&optional async subtreep visible-only body-only ext-plist)
"Export current buffer as an ikiwiki markdown file.
See org-md-export-to-markdown for full docs"
(require 'ox)
(interactive)
(let ((file (org-export-output-file-name ".mdwn" subtreep)))
(org-export-to-file 'ik file
async subtreep visible-only body-only ext-plist)))
See web-stacker for the background.
yantar92 on #org-mode pointed out that a derived backend would be
a cleaner solution. I had initially thought it was too complicated, but I have to agree the example in the org-mode documentation does
pretty much what I need.
This new approach has the big advantage that the generation of URLs happens at export time, so it's not possible for the displayed program code and the version encoded in the URL to get out of sync.
;; derived backend to customize src block handling
(defun my-beamer-src-block (src-block contents info)
"Transcode a SRC-BLOCK element from Org to beamer
CONTENTS is nil. INFO is a plist used as a communication
channel."
(let ((attr (org-export-read-attribute :attr_latex src-block :stacker)))
(concat
(when (or (not attr) (string= attr "both"))
(org-export-with-backend 'beamer src-block contents info))
(when attr
(let* ((body (org-element-property :value src-block))
(table '(? ?\n ?: ?/ ?? ?# ?[ ?] ?@ ?! ?$ ?& ??
?( ?) ?* ?+ ?, ?= ?%))
(slug (org-link-encode body table))
(simplified (replace-regexp-in-string "[%]20" "+" slug nil 'literal)))
(format "\n\\stackerlink{%s}" simplified))))))
(defun my-beamer-export-to-latex
(&optional async subtreep visible-only body-only ext-plist)
"Export current buffer as a (my)Beamer presentation (tex).
See org-beamer-export-to-latex for full docs"
(interactive)
(let ((file (org-export-output-file-name ".tex" subtreep)))
(org-export-to-file 'my-beamer file
async subtreep visible-only body-only ext-plist)))
(defun my-beamer-export-to-pdf
(&optional async subtreep visible-only body-only ext-plist)
"Export current buffer as a (my)Beamer presentation (PDF).
See org-beamer-export-to-pdf for full docs."
(interactive)
(let ((file (org-export-output-file-name ".tex" subtreep)))
(org-export-to-file 'my-beamer file
async subtreep visible-only body-only ext-plist
#'org-latex-compile)))
(with-eval-after-load "ox-beamer"
(org-export-define-derived-backend 'my-beamer 'beamer
:translate-alist '((src-block . my-beamer-src-block))
:menu-entry '(?l 1 ((?m "my beamer .tex" my-beamer-export-to-latex)
(?M "my beamer .pdf" my-beamer-export-to-pdf)))))
An example of using this in an org-document would as below. The first source code block generates only a link in the output while the last adds a generated link to the normal highlighted source code.
* Stuff
** Frame
#+attr_latex: :stacker t
#+NAME: last
#+BEGIN_SRC stacker :eval no
(f)
#+END_SRC
#+name: smol-example
#+BEGIN_SRC stacker :noweb yes
(defvar x 1)
(deffun (f)
(let ([y 2])
(deffun (h)
(+ x y))
(h)))
<<last>>
#+END_SRC
** Another Frame
#+ATTR_LATEX: :stacker both
#+begin_src smol :noweb yes
<<smol-example>>
#+end_src
The Emacs part is superceded by a cleaner approach
I the upcoming term I want to use KC Lu's web based stacker tool.
The key point is that it takes (small) programs encoded as part of the url.
Yesterday I spent some time integrating it into my existing
org-beamer workflow.
In my init.el I have
(defun org-babel-execute:stacker (body params)
(let* ((table '(? ?\n ?: ?/ ?? ?# ?[ ?] ?@ ?! ?$ ?& ??
?( ?) ?* ?+ ?, ?= ?%))
(slug (org-link-encode body table))
(simplified (replace-regexp-in-string "[%]20" "+" slug nil 'literal)))
(format "\\stackerlink{%s}" simplified)))
This means that when I "execute" the block below with C-c C-c, it updates the link, which is then embedded in the slides.
#+begin_src stacker :results value latex :exports both
(deffun (f x)
(let ([y 2])
(+ x y)))
(f 7)
#+end_src
#+RESULTS:
#+begin_export latex
\stackerlink{%28deffun+%28f+x%29%0A++%28let+%28%5By+2%5D%29%0A++++%28%2B+x+y%29%29%29%0A%28f+7%29}
#+end_export
The \stackerlink macro is probably fancier than needed. One could
just use \href from hyperref.sty, but I wanted to match the
appearence of other links in my documents (buttons in the margins).
This is based on a now lost answer from stackoverflow.com;
I think it wasn't this one, but you get the main idea: use \hyper@normalise.
\makeatletter
% define \stacker@base appropriately
\DeclareRobustCommand*{\stackerlink}{\hyper@normalise\stackerlink@}
\def\stackerlink@#1{%
\begin{tikzpicture}[overlay]%
\coordinate (here) at (0,0);%
\draw (current page.south west |- here)%
node[xshift=2ex,yshift=3.5ex,fill=magenta,inner sep=1pt]%
{\hyper@linkurl{\tiny\textcolor{white}{stacker}}{\stacker@base?program=#1}}; %
\end{tikzpicture}}
\makeatother
Problem description(s)
For some of its cheaper dedicated servers, OVH does not provide a KVM (in the virtual console sense) interface. Sometimes when a virtual console is provided, it requires a horrible java applet that won't run on modern systems without a lot of song and dance. Although OVH provides a few web based ways of installing,
- I prefer to use the debian installer image I'm used to and trust, and
- I needed some way to debug a broken install.
I have only tested this in the OVH rescue environment, but the general approach should work anywhere the rescue environment can install and run QEMU.
QEMU to the rescue
Initially I was horrified by the ovh forums post but eventually I realized it not only gave a way to install from a custom ISO, but provided a way to debug quite a few (but not all, as I discovered) boot problems by using the rescue env (which is an in-memory Debian Buster, with an updated kernel). The original solution uses VNC but that seemed superfluous to me, so I modified the procedure to use a "serial" console.
Preliminaries
- Set up a default ssh key in the OVH web console
- (re)boot into rescue mode
- ssh into root@yourhost (you might need to ignore changing host keys)
- cd /tmp
- You will need qemu (and may as well use kvm).
ovmfis needed for a UEFI bios.
apt install qemu-kvm ovmf
- Download the netinstaller iso
Download vmlinuz and initrd.gz that match your iso. In my case:
https://deb.debian.org/debian/dists/testing/main/installer-amd64/current/images/cdrom/
Doing the install
- Boot the installer in qemu. Here the system has two hard drives visible as /dev/sda and /dev/sdb.
qemu-system-x86_64 \
-enable-kvm \
-nographic \
-m 2048 \
-bios /usr/share/ovmf/OVMF.fd \
-drive index=0,media=disk,if=virtio,file=/dev/sda,format=raw \
-drive index=1,media=disk,if=virtio,file=/dev/sdb,format=raw \
-cdrom debian-bookworm-DI-alpha2-amd64-netinst.iso \
-kernel ./vmlinuz \
-initrd ./initrd.gz \
-append console=ttyS0,9600,n8
- Optionally follow Debian wiki to configure root on software raid.
- Make sure your disk(s) have an ESP partition.
- qemu and d-i are both using Ctrl-a as a prefix, so you need to C-a C-a 1 (e.g.) to switch terminals
- make sure you install ssh server, and a user account
Before leaving the rescue environment
- You may have forgotten something important, no problem you can boot the disks you just installed in qemu (I leave the apt here for convenient copy pasta in future rescue environments).
apt install qemu-kvm ovmf && \
qemu-system-x86_64 \
-enable-kvm \
-nographic \
-m 2048 \
-bios /usr/share/ovmf/OVMF.fd \
-drive index=0,media=disk,if=virtio,file=/dev/sda,format=raw \
-drive index=1,media=disk,if=virtio,file=/dev/sdb,format=raw \
-nic user,hostfwd=tcp:127.0.0.1:2222-:22 \
-boot c
One important gotcha is that the installer guess interface names based on the "hardware" it sees during the install. I wanted the network to work both in QEMU and in bare hardware boot, so I added a couple of link files. If you copy this, you most likely need to double check the PCI paths. You can get this information, e.g. from udevadm, but note you want to query in rescue env, not in QEMU, for the second case.
/etc/systemd/network/50-qemu-default.link
[Match]
Path=pci-0000:00:03.0
Virtualization=kvm
[Link]
Name=lan0
/etc/systemd/network/50-hardware-default.link
[Match]
Path=pci-0000:03:00.0
Virtualization=no
[Link]
Name=lan0
- Then edit
/etc/network/interfacesto refer tolan0
Spiffy new terminal emulators seem to come with their own terminfo
definitions. Venerable hosts that I ssh into tend not to know about
those. kitty comes with a thing to transfer that definition, but it
breaks if the remote host is running tcsh (don't ask). Similary the
one liner for alacritty on the arch wiki seems to assume the remote
shell is bash. Forthwith, a dumb shell script that works to send the
terminfo of the current terminal emulator to the remote host.
EDIT: Jakub Wilk worked out this can be replaced with the oneliner
infocmp | ssh $host tic -x -
#!/bin/sh
if [ "$#" -ne 1 ]; then
printf "usage: sendterminfo host\n"
exit 1
fi
host="$1"
filename=$(mktemp terminfoXXXXXX)
cleanup () {
rm "$filename"
}
trap cleanup EXIT
infocmp > "$filename"
remotefile=$(ssh "$host" mktemp)
scp -q "$filename" "$host:$remotefile"
ssh "$host" "tic -x \"$remotefile\""
ssh "$host" rm "$remotefile"
Unfortunately schroot does not maintain CPU affinity 1. This means in
particular that parallel builds have the tendency to take over an
entire slurm managed server, which is kindof rude. I haven't had
time to automate this yet, but following demonstrates a simple
workaround for interactive building.
╭─ simplex:~
╰─% schroot --preserve-environment -r -c polymake
(unstable-amd64-sbuild)bremner@simplex:~$ echo $SLURM_CPU_BIND_LIST
0x55555555555555555555
(unstable-amd64-sbuild)bremner@simplex:~$ grep Cpus /proc/self/status
Cpus_allowed: ffff,ffffffff,ffffffff
Cpus_allowed_list: 0-79
(unstable-amd64-sbuild)bremner@simplex:~$ taskset $SLURM_CPU_BIND_LIST bash
(unstable-amd64-sbuild)bremner@simplex:~$ grep Cpus /proc/self/status
Cpus_allowed: 5555,55555555,55555555
Cpus_allowed_list: 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38,40,42,44,46,48,50,52,54,56,58,60,62,64,66,68,70,72,74,76,78
Next steps
In principle the schroot configuration parameter can be used to run
taskset before every command. In practice it's a bit fiddly because
you need a shell script shim (because the environment variable) and
you need to e.g. goof around with bind mounts to make sure that your
script is available in the chroot. And then there's combining with
ccache and eatmydata...
Background
So apparently there's this pandemic thing, which means I'm teaching "Alternate Delivery" courses now. These are just like online courses, except possibly more synchronous, definitely less polished, and the tuition money doesn't go to the College of Extended Learning. I figure I'll need to manage share videos, and our learning management system, in the immortal words of Marie Kondo, does not bring me joy. This has caused me to revisit the problem of sharing large files in an ikiwiki based site (like the one you are reading).
My goto solution for large file management is
git-annex. The last time I looked
at this (a decade ago or so?), I was blocked by git-annex using
symlinks and ikiwiki ignoring them for security related reasons.
Since then two things changed which made things relatively easy.
I started using the
rsync_commandikiwiki option to deploy my site.git-annexwent through several design iterations for allowing non-symlink access to large files.
TL;DR
In my ikiwiki config
# attempt to hardlink source files? (optimisation for large files)
hardlink => 1,
In my ikiwiki git repo
$ git annex init
$ git annex add foo.jpg
$ git commit -m'add big photo'
$ git annex adjust --unlock # look ikiwiki, no symlinks
$ ikiwiki --setup ~/.config/ikiwiki/client # rebuild my local copy, for review
$ ikiwiki --setup /home/bremner/.config/ikiwiki/rsync.setup --refresh # deploy
You can see the result at photo
I have lately been using org-mode literate programming to generate
example code and beamer slides from the same source. I hit a wall
trying to re-use functions in multiple files, so I came up with the
following hack. Thanks 'ngz' on #emacs and Charles Berry on the
org-mode list for suggestions and discussion.
(defun db-extract-tangle-includes ()
(goto-char (point-min))
(let ((case-fold-search t)
(retval nil))
(while (re-search-forward "^#[+]TANGLE_INCLUDE:" nil t)
(let ((element (org-element-at-point)))
(when (eq (org-element-type element) 'keyword)
(push (org-element-property :value element) retval))))
retval))
(defun db-ob-tangle-hook ()
(let ((includes (db-extract-tangle-includes)))
(mapc #'org-babel-lob-ingest includes)))
(add-hook 'org-babel-pre-tangle-hook #'db-ob-tangle-hook t)
Use involves something like the following in your org-file.
#+SETUPFILE: presentation-settings.org
#+SETUPFILE: tangle-settings.org
#+TANGLE_INCLUDE: lecture21.org
#+TITLE: GC V: Mark & Sweep with free list
For batch export with make, I do something like [[!format Error: unsupported page format make]]
What?
I previously posted about my extremely quick-and-dirty buildinfo database using buildinfo-sqlite. This year at DebConf, I re-implimented this using PostgreSQL backend, added into some new features.
There is already buildinfo and buildinfos. I was informed I need to think up a name that clearly distinguishes from those two. Thus I give you builtin-pho.
There's a README for how to set up a local database. You'll need 12GB of disk space for the buildinfo files and another 4GB for the database (pro tip: you might want to change the location of your PostgreSQL data_directory, depending on how roomy your /var is)
Demo 1: find things build against old / buggy Build-Depends
select distinct p.source,p.version,d.version, b.path
from
binary_packages p, builds b, depends d
where
p.suite='sid' and b.source=p.source and
b.arch_all and p.arch = 'all'
and p.version = b.version
and d.id=b.id and d.depend='dh-elpa'
and d.version < debversion '1.16'
Demo 2: find packages in sid without buildinfo files
select distinct p.source,p.version
from
binary_packages p
where
p.suite='sid'
except
select p.source,p.version
from binary_packages p, builds b
where
b.source=p.source
and p.version=b.version
and ( (b.arch_all and p.arch='all') or
(b.arch_amd64 and p.arch='amd64') )
Disclaimer
Work in progress by an SQL newbie.
1 Background
Apparently motivated by recent phishing attacks against @unb.ca
addresses, UNB's Integrated Technology Services unit (ITS) recently
started adding banners to the body of email messages. Despite
(cough) several requests, they have been unable and/or unwilling to
let people opt out of this. Recently ITS has reduced the size of
banner; this does not change the substance of what is discussed here.
In this blog post I'll try to document some of the reasons this
reduces the utility of my UNB email account.
2 What do I know about email?
I have been using email since 1985 1. I have administered my own UNIX-like systems since
the mid 1990s. I am a Debian Developer 2.
Debian is a mid-sized organization (there are more Debian Developers
than UNB faculty members) that functions mainly via email (including
discussions and a bug tracker). I maintain a mail user agent
(informally, an email client) called notmuch
3. I administer my own (non-UNB) email
server. I have spent many hours reading RFCs 4.
In summary, my perspective might be different than an enterprise email
adminstrator, but I do know something about the nuts and bolts of how
email works.
3 What's wrong with a helpful message?
3.1 It's a banner ad.
I don't browse the web without an ad-blocker and I don't watch TV with advertising in it. Apparently the main source of advertising in my life is a service provided by my employer. Some readers will probably dispute my description of a warning label inserted by an email provider as "advertising". Note that is information inserted by a third party to promote their own (well intentioned) agenda, and inserted in an intentionally attention grabbing way. Advertisements from charities are still advertisements. Preventing phishing attacks is important, but so are an almost countless number of priorities of other units of the University. For better or worse those units are not so far able to insert messages into my email. As a thought experiment, imagine inserting a banner into every PDF file stored on UNB servers reminding people of the fiscal year end.
3.2 It makes us look unprofessional.
Because the banner is contained in the body of email messages, it almost inevitably ends up in replies. This lets funding agencies, industrial partners, and potential graduate students know that we consider them as potentially hostile entities. Suggesting that people should edit their replies is not really an acceptable answer, since it suggests that it is acceptable to download the work of maintaining the previous level of functionality onto each user of the system.
3.3 It doesn't help me
I have an archive of 61270 email messages received since 2003. Of
these 26215 claim to be from a unb.ca address 5. So historically
about 42% of the mail to arrive at my UNB mailbox is internal 6. This means that warnings will occur
in the majority of messages I receive. I think the onus is on the
proposer to show that a warning that occurs in the large majority of
messages will have any useful effect.
3.4 It disrupts my collaboration with open-source projects
Part of my job is to collaborate with various open source projects. A
prominent example is Eclipse OMR 7,
the technological driver for a collaboration with IBM that has brought
millions of dollars of graduate student funding to UNB. Git is now
the dominant version control system for open source projects, and one
popular way of using git is via git-send-email 8
Adding a banner breaks the delivery of patches by this method. In the a previous experiment I did about a month ago, it "only" caused the banner to end up in the git commit message. Those of you familiar with software developement will know that this is roughly the equivalent of walking out of the bathroom with toilet paper stuck to your shoe. You'd rather avoid it, but it's not fatal. The current implementation breaks things completely by quoted-printable re-encoding the message. In particular '=' gets transformed to '=3D' like the following
-+ gunichar *decoded=g_utf8_to_ucs4_fast (utf8_str, -1, NULL); -+ const gunichar *p = decoded; ++ gunichar *decoded=3Dg_utf8_to_ucs4_fast (utf8_str, -1, NULL);
I'm not currently sure if this is a bug in git or some kind of failure in the re-encoding. It would likely require an investment of several hours of time to localize that.
3.5 It interferes with the use of cryptography.
Unlike many people, I don't generally read my email on a phone. This
means that I don't rely on the previews that are apparently disrupted
by the presence of a warning banner. On the other hand I do send and
receive OpenPGP signed and encrypted messages. The effects of the
banner on both signed and encrypted messages is similar, so I'll stick
to discussing signed messages here. There are two main ways of signing
a message. The older method, still unfortunately required for some
situations is called "inline PGP". The signed region is re-encoded,
which causes gpg to issue a warning about a buggy MTA 9, namely gpg: quoted printable character in armor -
probably a buggy MTA has been used. This is not exactly confidence
inspiring. The more robust and modern standard is PGP/MIME. Here the
insertion of a banner does not provoke warnings from the cryptography
software, but it does make it much harder to read the message (before
and after screenshots are given below). Perhaps more importantly it
changes the message from one which is entirely signed or encrypted
10, to
one which is partially signed or encrypted. Such messages were
instrumental in the EFAIL exploit 11 and will
probably soon be rejected by modern email clients.
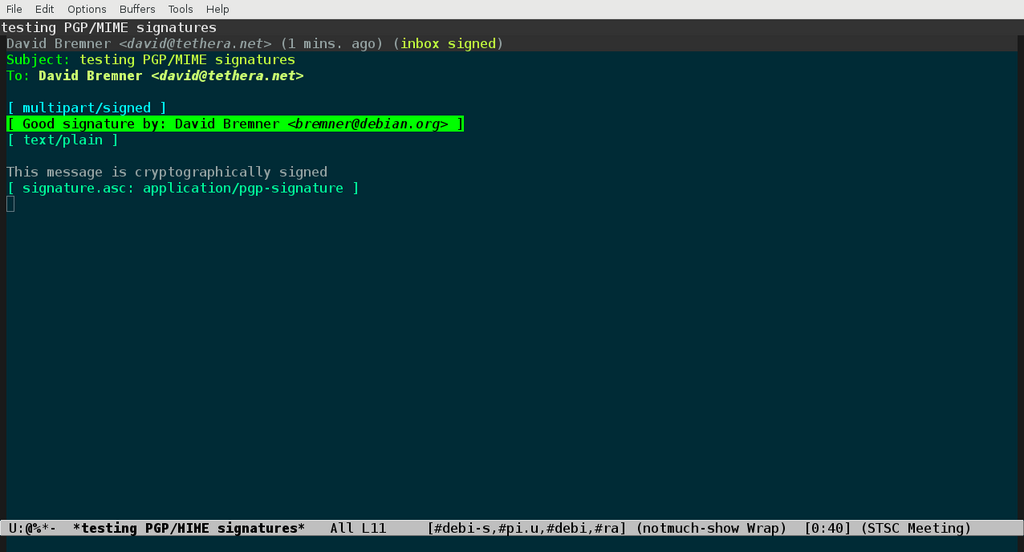
Figure 1: Intended view of PGP/MIME signed message
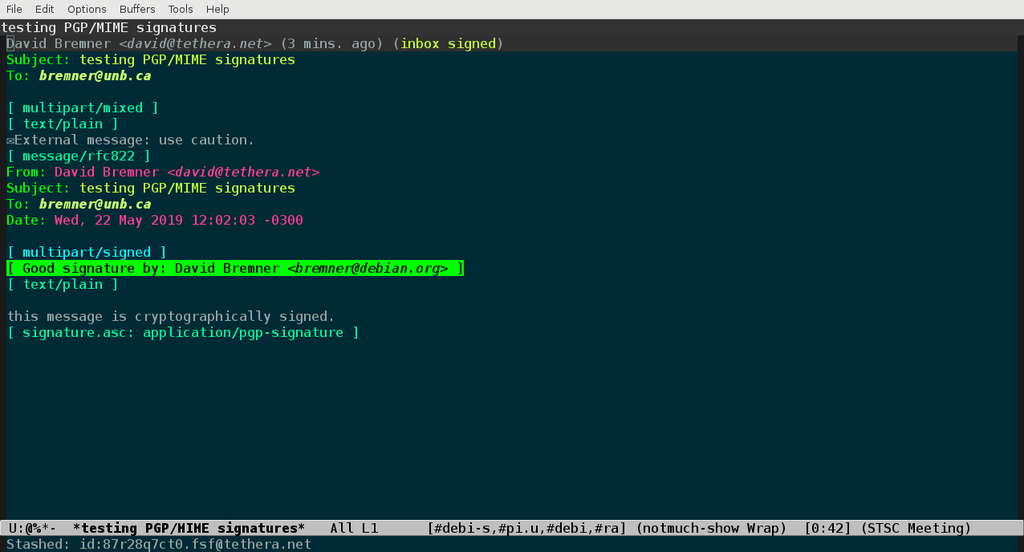
Figure 2: View with added banner
Footnotes:
On Multics, when I was a high school student
IETF Requests for Comments, which define most of the standards used by email systems.
possibly overcounting some spam as UNB originating email
In case it's not obvious dear reader, communicating with the world outside UNB is part of my job.
Some important projects function exclusively that way. See https://git-send-email.io/ for more information.
Mail Transfer Agent
Created: 2019-05-22 Wed 17:04
Emacs
2018-07-23
- NMUed cdargs
- NMUed silversearcher-ag-el
- Uploaded the partially unbundled emacs-goodies-el to Debian unstable
- packaged and uploaded graphviz-dot-mode
2018-07-24
- packaged and uploaded boxquote-el
- uploaded apache-mode-el
- Closed bugs in graphviz-dot-mode that were fixed by the new version.
- filed lintian bug about empty source package fields
2018-07-25
- packaged and uploaded emacs-session
- worked on sponsoring tabbar-el
2018-07-25
- uploaded dh-make-elpa
Notmuch
2018-07-2[23]
Wrote patch series to fix bug noticed by seanw while (seanw was) working working on a package inspired by policy workflow.
2018-07-25
- Finished reviewing a patch series from dkg about protected headers.
2018-07-26
Helped sean w find right config option for his bug report
Reviewed change proposal from aminb, suggested some issues to watch out for.
2018-07-27
- Add test for threading issue.
Nullmailer
2018-07-25
- uploaded nullmailer backport
2018-07-26
- add "envelopefilter" feature to remotes in nullmailer-ssh
Perl
2018-07-23
- Tried to figure out what documented BibTeX syntax is.
- Looked at BibTeX source.
- Ran away.
2018-07-24
- Forwarded #704527 to https://rt.cpan.org/Ticket/Display.html?id=125914
2018-07-25
- Uploaded libemail-abstract-perl to fix Vcs-* urls
- Updated debhelper compat and Standards-Version for libemail-thread-perl
- Uploaded libemail-thread-perl
2018-07-27
- fixed RC bug #904727 (blocking for perl transition)
Policy and procedures
2018-07-22
- seconded #459427
2018-07-23
- seconded #813471
- seconded #628515
2018-07-25
- read and discussed draft of salvaging policy with Tobi
2018-07-26
- Discussed policy bug about short form License and License-Grant
2018-07-27
- worked with Tobi on salvaging proposal
Introduction
Debian is currently collecting buildinfo but they are not very conveniently searchable. Eventually Chris Lamb's buildinfo.debian.net may solve this problem, but in the mean time, I decided to see how practical indexing the full set of buildinfo files is with sqlite.
Hack
First you need a copy of the buildinfo files. This is currently about 2.6G, and unfortunately you need to be a debian developer to fetch it.
$ rsync -avz mirror.ftp-master.debian.org:/srv/ftp-master.debian.org/buildinfo .Indexing takes about 15 minutes on my 5 year old machine (with an SSD). If you index all dependencies, you get a database of about 4G, probably because of my natural genius for database design. Restricting to debhelper and dh-elpa, it's about 17M.
$ python3 index.pyYou need at least
python3-debianinstalledNow you can do queries like
$ sqlite3 depends.sqlite "select * from depends where depend='dh-elpa' and depend_version<='0106'"where 0106 is some adhoc normalization of 1.6
Conclusions
The version number hackery is pretty fragile, but good enough for my current purposes. A more serious limitation is that I don't currently have a nice (and you see how generous my definition of nice is) way of limiting to builds currently available e.g. in Debian unstable.
Today I was wondering about converting a pdf made from scan of a book
into djvu, hopefully to reduce the size, without too much loss of
quality. My initial experiments with
pdf2djvu were a bit
discouraging, so I invested some time building
gsdjvu in order to be able
to run djvudigital.
Watching the messages from djvudigital I realized that the reason it
was achieving so much better compression was that it was using black
and white for the foreground layer by default. I also figured out that
the default 300dpi looks crappy since my source document is apparently
600dpi.
I then went back an compared djvudigital to pdf2djvu a bit more
carefully. My not-very-scientific conclusions:
- monochrome at higher resolution is better than coloured foreground
- higher resolution and (a little) lossy beats lower resolution
- at the same resolution,
djvudigitalgives nicer output, but at the same bit rate, comparable results are achievable withpdf2djvu.
Perhaps most compellingly, the output from pdf2djvu has sensible
metadata and is searchable in evince. Even with the --words option,
the output from djvudigital is not. This is possibly related to the
error messages like
Can't build /Identity.Unicode /CIDDecoding resource. See gs_ciddc.ps .
It could well be my fault, because building gsdjvu involved guessing at corrections for several errors.
comparing
GS_VERSIONto 900 doesn't work well, whenGS_VERSIONis a 5 digit number.GS_REVISIONseems to be what's wanted there.extra declaration of struct timeval deleted
-lz added to command to build mkromfs
Some of these issues have to do with building software from 2009 (the
instructions suggestion building with ghostscript 8.64) in a modern
toolchain; others I'm not sure. There was an upload of gsdjvu in
February of 2015, somewhat to my surprise. AT&T has more or less
crippled the project by licensing it under the CPL, which means
binaries are not distributable, hence motivation to fix all the rough
edges is minimal.
| Version | kilobytes per page | position in figure |
|---|---|---|
| Original PDF | 80.9 | top |
| pdf2djvu --dpi=450 | 92.0 | not shown |
| pdf2djvu --monochrome --dpi=450 | 27.5 | second from top |
| pdf2djvu --monochrome --dpi=600 --loss-level=50 | 21.3 | second from bottom |
| djvudigital --dpi=450 | 29.4 | bottom |

After a mildly ridiculous amount of effort I made a bootable-usb key.
I then layered a bash script on top of a perl script on top of gpg. What could possibly go wrong?
#!/bin/bash
infile=$1
keys=$(gpg --with-colons $infile | sed -n 's/^pub//p' | cut -f5 -d: )
gpg --homedir $HOME/.caff/gnupghome --import $infile
caff -R -m no "${keys[*]}"
today=$(date +"%Y-%m-%d")
output="$(pwd)/keys-$today.tar"
for key in ${keys[*]}; do
(cd $HOME/.caff/keys/; tar rvf "$output" $today/$key.mail*)
done
The idea is that keys are exported to files on a networked host, the files are processed on an offline host, and the resulting tarball of mail messages sneakernetted back to the connected host.
Umm. Somehow I thought this would be easier than learning about live-build. Probably I was wrong. There are probably many better tutorials on the web.
Two useful observations: zeroing the key can eliminate mysterious grub errors, and systemd-nspawn is pretty handy. One thing that should have been obvious, but wasn't to me is that it's easier to install grub onto a device outside of any container.
Find device
$ dmesg
Count sectors
# fdisk -l /dev/sdx
Assume that every command after here is dangerous.
Zero it out. This is overkill for a fresh key, but fixed a problem with reusing a stick that had a previous live distro installed on it.
# dd if=/dev/zero of=/dev/sdx bs=1048576 count=$count
Where $count is calculated by dividing the sector count by 2048.
Make file system. There are lots of options. I eventually used parted
# parted
(parted) mklabel msdos
(parted) mkpart primary ext2 1 -1
(parted) set 1 boot on
(parted) quit
Make a file system
# mkfs.ext2 /dev/sdx1
# mount /dev/sdx1 /mnt
Install the base system
# debootstrap --variant=minbase jessie /mnt http://httpredir.debian.org/debian/
Install grub (no chroot needed)
# grub-install --boot-directory /mnt/boot /dev/sdx1
Set a root password
# chroot /mnt
# passwd root
# exit
create up fstab
# blkid -p /dev/sdc1 | cut -f2 -d' ' > /mnt/etc/fstab
Now edit to fix syntax, tell ext2, etc...
Now switch to system-nspawn, to avoid boring bind mounting, etc..
# systemd-nspawn -b -D /mnt
login to the container, install linux-base, linux-image-amd64, grub-pc
EDIT: fixed block size of dd, based on suggestion of tg. EDIT2: fixed count to match block size
I've been a mostly happy Thinkpad owner for almost 15 years. My first Thinkpad was a 570, followed by an X40, an X61s, and an X220. There might have been one more in there, my archives only go back a decade. Although it's lately gotten harder to buy Thinkpads at UNB as Dell gets better contracts with our purchasing people, I've persevered, mainly because I'm used to the Trackpoint, and I like the availability of hardware service manuals. Overall I've been pleased with the engineering of the X series.
Over the last few days I learned about the installation of the superfish malware on new Lenovo systems, and Lenovo's completely inadequate response to the revelation. I don't use Windows, so this malware would not have directly affected me (unless I had the misfortune to use this system to download installation media for some GNU/Linux distribution). Nonetheless, how can I trust the firmware installed by a company that seems to value its users' security and privacy so little?
Unless Lenovo can show some sign of understanding the gravity of this mistake, and undertake not to repeat it, then I'm afraid you will be joining Sony on my list of vendors I used to consider buying from. Sure, it's only a gross income loss of $500 a year or so, if you assume I'm alone in this reaction. I don't think I'm alone in being disgusted and angered by this incident.
(Debian) packaging and Git.
The big picture is as follows. In my view, the most natural way to
work on a packaging project in version control [1] is to have an
upstream branch which either tracks upstream Git/Hg/Svn, or imports of
tarballs (or some combination thereof, and a Debian branch where both
modifications to upstream source and commits to stuff in ./debian are
added [2]. Deviations from this are mainly motivated by a desire to
export source packages, a version control neutral interchange format
that still preserves the distinction between upstream source and
distro modifications. Of course, if you're happy with the distro
modifications as one big diff, then you can stop reading now gitpkg
$debian_branch $upstream_branch and you're done. The other easy case
is if your changes don't touch upstream; then 3.0 (quilt) packages
work nicely with ./debian in a separate tarball.
So the tension is between my preferred integration style, and making
source packages with changes to upstream source organized in some
nice way, preferably in logical patches like, uh, commits in a
version control system. At some point we may be able use some form of
version control repo as a source package, but the issues with that are
for another blog post. At the moment then we are stuck with
trying bridge the gap between a git repository and a 3.0 (quilt)
source package. If you don't know the details of Debian packaging,
just imagine a patch series like you would generate with git
format-patch or apply with (surprise) quilt.
From Git to Quilt.
The most obvious (and the most common) way to bridge the gap between
git and quilt is to export patches manually (or using a helper like
gbp-pq) and commit them to the packaging repository. This has the
advantage of not forcing anyone to use git or specialized helpers to
collaborate on the package. On the other hand it's quite far from the
vision of using git (or your favourite VCS) to do the integration that
I started with.
The next level of sophistication is to maintain a branch of
upstream-modifying commits. Roughly speaking, this is the approach
taken by git-dpm, by gitpkg, and with some additional friction
from manually importing and exporting the patches, by gbp-pq. There
are some issues with rebasing a branch of patches, mainly it seems to
rely on one person at a time working on the patch branch, and it
forces the use of specialized tools or workflows. Nonetheless, both
git-dpm and gitpkg support this mode of working reasonably well [3].
Lately I've been working on exporting patches from (an immutable) git
history. My initial experiments with marking commits with git notes
more or less worked [4]. I put this on the back-burner for two
reasons, first sharing git notes is still not very well supported by
git itself [5], and second Gitpkg maintainer Ron Lee convinced me to
automagically pick out what patches to export. Ron's motivation (as I
understand it) is to have tools which work on any git repository
without extra metadata in the form of notes.
Linearizing History on the fly.
After a few iterations, I arrived at the following specification.
The user supplies two refs upstream and head. upstream should be suitable for export as a
.orig.tar.gzfile [6], and it should be an ancestor of head.At source package build time, we want to construct a series of patches that
- Is guaranteed to apply to upstream
- Produces the same work tree as head, outside
./debian - Does not touch
./debian - As much as possible, matches the git history from upstream to head.
Condition (4) suggests we want something roughly like git
format-patch upstream..head, removing those patches which are
only about Debian packaging. Because of (3), we have to be a bit
careful about commits that touch upstream and ./debian. We also
want to avoid outputting patches that have been applied (or worse
partially applied) upstream. git patch-id can help identify
cherry-picked patches, but not partial application.
Eventually I arrived at the following strategy.
Use git-filter-branch to construct a copy of the history upstream..head with ./debian (and for technical reasons .pc) excised.
Filter these commits to remove e.g. those that are present exactly upstream, or those that introduces no changes, or changes unrepresentable in a patch.
Try to revert the remaining commits, in reverse order. The idea here is twofold. First, a patch that occurs twice in history because of merging will only revert the most recent one, allowing earlier copies to be skipped. Second, the state of the temporary branch after all successful reverts represents the difference from upstream not accounted for by any patch.
Generate a "fixup patch" accounting for any remaining differences, to be applied before any if the "nice" patches.
Cherry-pick each "nice" patch on top of the fixup patch, to ensure we have a linear history that can be exported to quilt. If any of these cherry-picks fail, abort the export.
Yep, it seems over-complicated to me too.
TL;DR: Show me the code.
You can clone my current version from
git://pivot.cs.unb.ca/gitpkg.git
This provides a script "git-debcherry" which does the history linearization discussed above. In order to test out how/if this works in your repository, you could run
git-debcherry --stat $UPSTREAM
For actual use, you probably want to use something like
git-debcherry -o debian/patches
There is a hook in hooks/debcherry-deb-export-hook that does this at
source package export time.
I'm aware this is not that fast; it does several expensive operations. On the other hand, you know what Don Knuth says about premature optimization, so I'm more interested in reports of when it does and doesn't work. In addition to crashing, generating multi-megabyte "fixup patch" probably counts as failure.
Notes
This first part doesn't seem too Debian or git specific to me, but I don't know much concrete about other packaging workflows or other version control systems.
Another variation is to have a patched upstream branch and merge that into the Debian packaging branch. The trade-off here that you can simplify the patch export process a bit, but the repo needs to have taken this disciplined approach from the beginning.
git-dpm merges the patched upstream into the Debian branch. This makes the history a bit messier, but seems to be more robust. I've been thinking about trying this out (semi-manually) for gitpkg.
See e.g. exporting. Although I did not then know the many surprising and horrible things people do in packaging histories, so it probably didn't work as well as I thought it did.
It's doable, but one ends up spending about a bunch lines of code on duplicating basic git functionality; e.g. there is no real support for tags of notes.
Since as far as I know quilt has no way of deleting files except to list the content, this means in particular exporting upstream should yield a DFSG Free source tree.
In April of 2012 I bought a ColorHug colorimeter. I got a bit discouraged when the first thing I realized was that one of my monitors needed replacing, and put the the colorhug in a drawer until today.
With quite a lot of help and encouragment from Pascal de Bruijn, I finally got it going. Pascal has written an informative blog post on color management. That's a good place to look for background. This is more of a "write down the commands so I don't forget" sort of blog post, but it might help somebody else trying to calibrate their monitor using argyll on the command line. I'm not running gnome, so using gnome color manager turns out to be a bit of a hassle.
I run Debian Wheezy on this machine, and I'll mention the packages I used, even though I didn't install most of them today.
Find the masking tape, and tear off a long enough strip to hold the ColorHug on the monitor. This is probably the real reason I gave up last time; it takes about 45minutes to run the calibration, and I lack the attention span/upper-arm-strength to hold the sensor up for that long. Apparently new ColorHugs are shipping with some elastic.
Update the firmware on the colorhug. This is a gui-wizard kindof thing.
% apt-get install colorhug-client % colorhug-flashSet the monitor to factory defaults. On this ASUS PA238QR, that is brightness 100, contrast 80, R=G=B=100. I adjusted the brightness down to about 70; 100 is kindof eye-burning IMHO.
Figure out which display is which; I have two monitors.
% dispwin -\?Look under "-d n"
Do the calibration. This is really verbatim from Pascal, except I added the
ENABLE_COLORHUG=trueand-d 2bits.% apt-get install argyll % ENABLE_COLORHUG=true dispcal -v -d 2 -m -q m -y l -t 6500 -g 2.2 test % targen -v -d 3 -G -f 128 test % ENABLE_COLORHUG=true dispread -v -d 2 -y l -k test.cal test % colprof -v -A "make" -M "model" -D "make model desc" -C "copyright" -q m -a G testLoad the profile
% dispwin -d 2 -I test.iccIt seems this only loads the x property
_ICC_PROFILE_1instead of_ICC_PROFILE; whether this works for a particular application seems to be not 100% guaranteed. It seems ok for darktable and gimp.
It's spring, and young(ish?) hackers' minds turn to OpenCL. What is the state of things? I haven't the faintest idea, but I thought I'd try to share what I find out. So far, just some links. Details to be filled in later, particularly if you, dear reader, tell them to me.
Specification
LLVM based front ends
Mesa backend
Rumours/hopes of something working in mesa 8.1?
- r600g is merged into master as of this writing.
- clover
Other projects
- SNU This project seems be only for Cell/ARM/DSP at the moment. Although they make you register to download, it looks like it is LGPL.
I've been experimenting with a new packaging tool/workflow based on marking certain commits on my integration branch for export as quilt patches. In this post I'll walk though converting the package nauty to this workflow.
Add a control file for the gitpkg export hook, and enable the hook: (the package is already 3.0 (quilt))
% echo ':debpatch: upstream..master' > debian/source/git-patches % git add debian/source/git-patches && git commit -m'add control file for gitpkg quilt export' % git config gitpkg.deb-export-hook /usr/share/gitpkg/hooks/quilt-patches-deb-export-hookThis says that all commits reachable from master but not from upstream should be checked for possible export as quilt patches.
This package was previously maintained in the "recommend topgit style" with the patches checked in on a seperate branch, so grab a copy.
% git archive --prefix=nauty/ build | (cd /tmp ; tar xvf -)More conventional git-buildpackage style packaging would not need this step.
Import the patches. If everything is perfect, you can use qit quiltimport, but I have several patches not listed in "series", and quiltimport ignores series, so I have to do things by hand.
% git am /tmp/nauty/debian/patches/feature/shlib.diffMark my imported patch for export.
% git debpatch +export HEADgit debpatch listoutputs the followingafb2c20 feature/shlib Export: true makefile.in | 241 +++++++++++++++++++++++++++++++++-------------------------- 1 files changed, 136 insertions(+), 105 deletions(-)The first line is the subject line of the patch, followed by any notes from debpatch (in this case, just 'Export: true'), followed by a diffstat. If more patches were marked, this would be repeated for each one.
In this case I notice subject line is kindof cryptic and decide to amend.
git commit --amendgit debpatch liststill shows the same thing, which highlights a fundemental aspect of git notes: they attach to commits. And I just made a new commit, sogit debpatch -export afb2c20 git debpatch +export HEADNow
git debpatch listlooks ok, so we trygit debpatch exportas a dry run. In debian/patches we have0001-makefile.in-Support-building-a-shared-library-and-st.patch series
That looks good. Now we are not going to commit this, since one of our overall goal is to avoid commiting patches. To clean up the export,
rm -rf debian/patchesgitpkg masterexports a source package, and because I enabled the appropriate hook, I have the following% tar tvf ../deb-packages/nauty/nauty_2.4r2-1.debian.tar.gz | grep debian/patches drwxr-xr-x 0/0 0 2012-03-13 23:08 debian/patches/ -rw-r--r-- 0/0 143 2012-03-13 23:08 debian/patches/series -rw-r--r-- 0/0 14399 2012-03-13 23:08 debian/patches/0001-makefile.in-Support-building-a-shared-library-and-st.patchNote that these patches are exported straight from git.
I'm done for now so
git push git debpatch push
the second command is needed to push the debpatch notes metadata to the origin. There is a corresponding fetch, merge, and pull commands.
More info
Example package: bibutils In this package, I was already maintaining the upstream patches merged into my master branch; I retroactively added the quilt export.
I have been in the habit of using R to make e.g. histograms of test scores in my courses. The main problem is that I don't really need (or am too ignorant to know that I need) the vast statistical powers of R, and I use it rarely enough that its always a bit of a struggle to get the plot I want.
racket is a programming language in the scheme family, distinguished from some of its more spartan cousins by its "batteries included" attitude.
I recently stumbled upon the PLoT graph (information visualization kind, not networks) plotting module and was pretty impressed with the Snazzy 3D Pictures.
So this time I decided try using PLoT for my chores. It worked out pretty well; of course I am not very ambitious. Compared to using R, I had to do a bit more work in data preparation, but it was faster to write the Racket than to get R to do the work for me (again, probably a matter of relative familiarity).
#lang racket/base
(require racket/list)
(require plot)
(define marks (build-list 30 (lambda (n) (random 25))))
(define out-of 25)
(define breaks '((0 9) (10 12) (13 15) (16 18) (19 21) (22 25)))
(define (per-cent n)
(ceiling (* 100 (/ n out-of))))
(define (label l)
(format "~a-~a" (per-cent (first l)) (per-cent (second l))))
(define (buckets l)
(let ((sorted (sort l <)))
(for/list ([b breaks])
(vector (label b)
(count (lambda (x) (and
(<= x ( second b))
(>= x ( first b))))
marks)))))
(plot
(list
(discrete-histogram
(buckets marks)))
#:out-file "racket-hist.png")
It seems kind of unfair, given the name, but duplicity really doesn't like to be run in parallel. This means that some naive admin (not me of course, but uh, this guy I know ;) ) who writes a crontab
@daily duplicity incr $ARGS $SRC $DEST
@weekly duplicity full $ARGS $SRC $DEST
is in for a nasty surprise when both fire at the same time. In particular one of them will terminate with the not very helpful.
AttributeError: BackupChain instance has no attribute 'archive_dir'
After some preliminary reading of mailing list archives, I decided to
delete ~/.cache/duplicity on the client and try again. This was
not a good move.
- It didn't fix the problem
- Resyncing from the server required decrypting some information, which required access to the gpg private key.
Now for me, one of the main motivations for using duplicity was that I could encrypt to a key without having the private key accessible. Luckily the following crazy hack works.
A host where the gpg private key is accessible, delete the
~/.cache/duplicity, and perform some arbitrary duplicity operation. I didduplicity clean $DEST
UPDATE: for this hack to work, at least with s3 backend, you need to specifify the same arguments. In particular omitting --s3-use-new-style will cause mysterious failures. Also, --use-agent may help.
- Now rsync the ./duplicity/cache directory to the backup client.
Now at first you will be depressed, because the problem isn't fixed yet. What you need to do is go onto the backup server (in my case Amazon s3) and delete one of the backups (in my case, the incremental one). Of course, if you are the kind of reader who skips to the end, probably just doing this will fix the problem and you can avoid the hijinks.
And, uh, some kind of locking would probably be a good plan... For now I just stagger the cron jobs.
As of version 0.17, gitpkg ships with a hook called quilt-patches-deb-export-hook. This can be used to export patches from git at the time of creating the source package.
This is controlled by a file debian/source/git-patches.
Each line contains a range suitable for passing to git-format-patch(1).
The variables UPSTREAM_VERSION and DEB_VERSION are replaced with
values taken from debian/changelog. Note that $UPSTREAM_VERSION is
the first part of $DEB_VERSION
An example is
upstream/$UPSTREAM_VERSION..patches/$DEB_VERSION
upstream/$UPSTREAM_VERSION..embedded-libs/$DEB_VERSION
This tells gitpkg to export the given two ranges of commits to debian/patches while generating the source package. Each commit becomes a patch in debian/patches, with names generated from the commit messages. In this example, we get 5 patches from the two ranges.
0001-expand-pattern-in-no-java-rule.patch
0002-fix-dd_free_global_constants.patch
0003-Backported-patch-for-CPlusPlus-name-mangling-guesser.patch
0004-Use-system-copy-of-nauty-in-apps-graph.patch
0005-Comment-out-jreality-installation.patch
Thanks to the wonders of 3.0 (quilt) packages, these are applied
when the source package is unpacked.
Caveats.
Current lintian complains bitterly about debian/source/git-patches. This should be fixed with the next upload.
It's a bit dangerous if you checkout such package from git, don't read any of the documentation, and build with debuild or something similar, since you won't get the patches applied. There is a proposed check that catches most of such booboos. You could also cause the build to fail if the same error is detected; this a matter of personal taste I guess.
I use a lot of code in my lectures, in many different programming languages.
I use highlight to generate HTML (via ikiwiki) for web pages.
For class presentations, I mostly use the beamer LaTeX class.
In order to simplify generating overlays, I wrote a perl script hl-beamer.pl to preprocess source code. An htmlification of the documention/man-page follows.
NAME
hl-beamer - Preprocessor for hightlight to generate beamer overlays.
SYNOPSIS
hl-beamer -c // InstructiveExample.java | highlight -S java -O latex > figure1.tex
DESCRIPTION
hl-beamer looks for single line comments (with syntax specified by -c) These comments can start with @ followed by some codes to specify beamer overlays or sections (just chunks of text which can be selectively included).
OPTIONS
-c commentstring Start of single line comments
-k section1,section2 List of sections to keep (see @( below).
-s number strip number spaces from the front of every line (tabs are first converted to spaces using Text::Tabs::expand)
-S strip all directive comments.
CODES
@( section named section. Can be nested. Pass -k section to include in output. The same name can (usefully) be re-used. Sections omit and comment are omitted by default.
@) close most recent section.
@< [overlaytype] [overlayspec] define a beamer overlay. overlaytype defaults to visibleenv if not specified. overlayspec defaults to +- if not specified.
@> close most recent overlay
EXAMPLE
Example input follows. I would probably process this with
hl-beamer -s 4 -k encodeInner
Sample Input
// @( omit
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.io.Serializable;
import java.util.Scanner;
// @)
// @( encoderInner
private int findRun(int inRow, int startCol){
// @<
int value=bits[inRow][startCol];
int cursor=startCol;
// @>
// @<
while(cursor<columns &&
bits[inRow][cursor] == value)
//@<
cursor++;
//@>
// @>
// @<
return cursor-1;
// @>
}
// @)
BUGS AND LIMITATIONS
Currently overlaytype and section must consist of upper and lower case letters and or underscores. This is basically pure sloth on the part of the author.
Tabs are always expanded to spaces.
I recently decided to try maintaining a Debian package (bibutils) without committing any patches to Git. One of the disadvantages of this approach is that the patches for upstream are not nicely sorted out in ./debian/patches. I decided to write a little tool to sort out which commits should be sent to upstream. I'm not too happy about the length of it, or the name "git-classify", but I'm posting in case someone has some suggestions. Or maybe somebody finds this useful.
#!/usr/bin/perl
use strict;
my $upstreamonly=0;
if ($ARGV[0] eq "-u"){
$upstreamonly=1;
shift (@ARGV);
}
open(GIT,"git log -z --format=\"%n%x00%H\" --name-only @ARGV|");
# throw away blank line at the beginning.
$_=<GIT>;
my $sha="";
LINE: while(<GIT>){
chomp();
next LINE if (m/^\s*$/);
if (m/^\x0([0-9a-fA-F]+)/){
$sha=$1;
} else {
my $debian=0;
my $upstream=0;
foreach my $word ( split("\x00",$_) ) {
if ($word=~m@^debian/@) {
$debian++;
} elsif (length($word)>0) {
$upstream++;
}
}
if (!$upstreamonly){
print "$sha\t";
print "MIXED" if ($upstream>0 && $debian>0);
print "upstream" if ($upstream>0 && $debian==0);
print "debian" if ($upstream==0 && $debian>0);
print "\n";
} else {
print "$sha\n" if ($upstream>0 && $debian==0);
}
}
}
=pod
=head1 Name
git-classify - Classify commits as upstream, debian, or MIXED
=head1 Synopsis
=over
=item B<git classify> [I<-u>] [I<arguments for git-log>]
=back
=head1 Description
Classify a range of commits (specified as for git-log) as I<upstream>
(touching only files outside ./debian), I<debian> (touching files only
inside ./debian) or I<MIXED>. Presumably these last kind are to be
discouraged.
=head2 Options
=over
=item B<-u> output only the SHA1 hashes of upstream commits (as
defined above).
=back
=head1 Examples
Generate all likely patches to send upstream
git classify -u $SHA..HEAD | xargs -L1 git format-patch -1
Before I discovered you could just point your browser at
http://search.cpan.org/meta/Dist-Name-0.007/META.json to automagically
convert META.yml and META.json, I wrote a script to do it.
Anyway, it goes with my "I hate the cloud" prejudices :).
use CPAN::Meta;
use CPAN::Meta::Converter;
use Data::Dumper;
my $meta = CPAN::Meta->load_file("META.yml");
my $cmc = CPAN::Meta::Converter->new($meta);
my $new=CPAN::Meta->new($cmc->convert(version=>"2"));
$new->save("META.json");
It turns out that pdfedit is pretty good at extracting text from pdf files. Here is a script I wrote to do that in batch mode.
#!/bin/sh
# Print the text from a pdf document on stdout
# Copyright: (c) 2006-2010 PDFedit team <http://sourceforge.net/projects/pdfedit>
# Copyright: (c) 2010, David Bremner <david@tethera.net>
# Licensed under version 2 or later of the GNU GPL
set -e
if [ $# -lt 1 ]; then
echo usage: $0 file [pageSep]
exit 1
fi
#!/bin/sh
# Print the text from a pdf document on stdout
# Copyright: © 2006-2010 PDFedit team <http://sourceforge.net/projects/pdfedit>
# Copyright: © 2010, David Bremner <david@tethera.net>
# Licensed under version 2 or later of the GNU GPL
set -e
if [ $# -lt 1 ]; then
echo usage: $0 file [pageSep]
exit 1
fi
/usr/bin/pdfedit -console -eval '
function onConsoleStart() {
var inName = takeParameter();
var pageSep = takeParameter();
var doc = loadPdf(inName,false);
pages=doc.getPageCount();
for (i=1;i<=pages;i++) {
pg=doc.getPage(i);
text=pg.getText();
print(text);
print("\n");
print(pageSep);
}
}
' $1 $2
Yeah, I wish #!/usr/bin/pdfedit worked too. Thanks to Aaron M Ucko for pointing out that
-eval could replace the use of a temporary file.
Oh, and pdfedit will be even better when the authors release a new version that fixes truncating wide text
Dear Julien;
After using notmuch for a while, I came to the conclusion that tags are mostly irelevant. What is a game changer for me is fast global search. And yes, I changed from using dovecot search, so I mean much faster than that. Actually I remember that from the Human Computer Interface course that I took in the early Neolithic era that speed of response has been measured as a key factor in interfaces, so maybe it isn't just me.
Of course there are tradeoffs, some of which you mention.
David
What is it?
I was a bit daunted by the number of mails from people signing my gpg keys at debconf, so I wrote a script to mass process them. The workflow, for those of you using notmuch is as follows:
$ notmuch show --format=mbox tag:keysign > sigs.mbox
$ ffac sigs.mbox
where previously I have tagged keysigning emails as "keysign" if I want to import them. You also need to run gpg-agent, since I was too lazy/scared to deal with passphrases.
This will import them into a keyring in ~/.ffac; uploading is still
manual using something like
$ gpg --homedir=$HOME/.ffac --send-keys $keyid
UPDATE Before you upload all of those shiny signatures, you might
want to use the included script fetch-sig-keys to add the
corresponding keys to the temporary keyring in ~/.ffac.
After
$ fetch-sig-keys $keyid
then
$ gpg --homedir ~/.ffac --list-sigs $keyid
should have a UID associated with each signature.
How do I use it
At the moment this is has been tested once or twice by one
person. More testing would be great, but be warned this is pre-release
software until you can install it with apt-get.
Get the script from
$ git clone git://pivot.cs.unb.ca/git/ffac.git
Get a patched version of Mail::GnuPG that supports
gpg-agent; hopefully this will make it upstream, but for now,$ git clone git://pivot.cs.unb.ca/git/mail-gnupg.git
I have a patched version of the debian package that I could make available if there was interest.
Install the other dependencies.
# apt-get install libmime-parser-perl libemail-folder-perl
UPDATED
2011/07/29 libmail-gnupg-perl in Debian supports gpg-agent for some time now.
racket (previously known as plt-scheme) is an
interpreter/JIT-compiler/development environment with about 6 years of
subversion history in a converted git repo. Debian packaging has been
done in subversion, with only the contents of ./debian in version
control. I wanted to merge these into a single git repository.
The first step is to create a repo and fetch the relevant history.
TMPDIR=/var/tmp
export TMPDIR
ME=`readlink -f $0`
AUTHORS=`dirname $ME`/authors
mkdir racket && cd racket && git init
git remote add racket git://git.racket-lang.org/plt
git fetch --tags racket
git config merge.renameLimit 10000
git svn init --stdlayout svn://svn.debian.org/svn/pkg-plt-scheme/plt-scheme/
git svn fetch -A$AUTHORS
git branch debian
A couple points to note:
At some point there were huge numbers of renames when then the project renamed itself, hense the setting for
merge.renameLimitNote the use of an authors file to make sure the author names and emails are reasonable in the imported history.
git svn creates a branch master, which we will eventually forcibly overwrite; we stash that branch as
debianfor later use.
Now a couple complications arose about upstream's git repo.
Upstream releases seperate source tarballs for unix, mac, and windows. Each of these is constructed by deleting a large number of files from version control, and occasionally some last minute fiddling with README files and so on.
The history of the release tags is not completely linear. For example,
rocinante:~/projects/racket (git-svn)-[master]-% git diff --shortstat v4.2.4 `git merge-base v4.2.4 v5.0`
48 files changed, 242 insertions(+), 393 deletions(-)
rocinante:~/projects/racket (git-svn)-[master]-% git diff --shortstat v4.2.1 `git merge-base v4.2.1 v4.2.4`
76 files changed, 642 insertions(+), 1485 deletions(-)
The combination made my straight forward attempt at constructing a history synched with release tarballs generate many conflicts. I ended up importing each tarball on a temporary branch, and the merges went smoother. Note also the use of "git merge -s recursive -X theirs" to resolve conflicts in favour of the new upstream version.
The repetitive bits of the merge are collected as shell functions.
import_tgz() {
if [ -f $1 ]; then
git clean -fxd;
git ls-files -z | xargs -0 rm -f;
tar --strip-components=1 -zxvf $1 ;
git add -A;
git commit -m'Importing '`basename $1`;
else
echo "missing tarball $1";
fi;
}
do_merge() {
version=$1
git checkout -b v$version-tarball v$version
import_tgz ../plt-scheme_$version.orig.tar.gz
git checkout upstream
git merge -s recursive -X theirs v$version-tarball
}
post_merge() {
version=$1
git tag -f upstream/$version
pristine-tar commit ../plt-scheme_$version.orig.tar.gz
git branch -d v$version-tarball
}
The entire merge script is here. A typical step looks like
do_merge 5.0
git rm collects/tests/stepper/automatic-tests.ss
git add `git status -s | egrep ^UA | cut -f2 -d' '`
git checkout v5.0-tarball doc/release-notes/teachpack/HISTORY.txt
git rm readme.txt
git add collects/tests/web-server/info.rkt
git commit -m'Resolve conflicts from new upstream version 5.0'
post_merge 5.0
Finally, we have the comparatively easy task of merging the upstream
and Debian branches. In one or two places git was confused by all of
the copying and renaming of files and I had to manually fix things up
with git rm.
cd racket || /bin/true
set -e
git checkout debian
git tag -f packaging/4.0.1-2 `git svn find-rev r98`
git tag -f packaging/4.2.1-1 `git svn find-rev r113`
git tag -f packaging/4.2.4-2 `git svn find-rev r126`
git branch -f master upstream/4.0.1
git checkout master
git merge packaging/4.0.1-2
git tag -f debian/4.0.1-2
git merge upstream/4.2.1
git merge packaging/4.2.1-1
git tag -f debian/4.2.1-1
git merge upstream/4.2.4
git merge packaging/4.2.4-2
git rm collects/tests/stxclass/more-tests.ss && git commit -m'fix false rename detection'
git tag -f debian/4.2.4-2
git merge -s recursive -X theirs upstream/5.0
git rm collects/tests/web-server/info.rkt
git commit -m 'Merge upstream 5.0'
I'm thinking about distributed issue tracking systems that play nice with git. I don't care about other version control systems anymore :). I also prefer command line interfaces, because as commentators on the blog have mentioned, I'm a Luddite (in the imprecise, slang sense).
So far I have found a few projects, and tried to guess how much of a going concern they are.
Git Specific
ticgit I don't know if this github at its best or worst, but the original project seems dormant and there are several forks. According the original author, this one is probably the best.
git-issues Originally a rewrite of ticgit in python, it now claims to be defunct.
VCS Agnostic
ditz Despite my not caring about other VCSs, ditz is VCS agnostic, just making files. Seems active.
cil takes a similar approach to ditz, is written in Perl rather than Ruby, and should release again any day now (hint, hint).
milli is a minimalist approach to the same theme.
Sortof VCS Agnostic
bugs everywhere is written in python. Works with Arch, Bazaar, Darcs, Git, and Mercurial. There seems to some on-going development activity.
simple defects has Git and Darcs integration. It seems active. It's written by bestpractical people, so no surprise it is written in Perl.
Updated
- 2010-10-01 Note activity for bugs everywhere
- 2012-06-22 Note git-issues self description as defunct. Update link for cil.
I'm collecting information (or at least links) about functional programming languages on the the JVM. I'm going to intentionally leave "functional programming language" undefined here, so that people can have fun debating :).
Functional Languages
Languages and Libraries with functional features
Projects and rumours.
There has been discussion about making the jhc target the jvm. They both start with 'j', so that is hopeful.
Java itself may (soon? eventually?) support closures
You have a gitolite install on host $MASTER, and you want a mirror on $SLAVE. Here is one way to do that. $CLIENT is your workstation, that need not be the same as $MASTER or $SLAVE.
On $CLIENT, install gitolite on $SLAVE. It is ok to re-use your gitolite admin key here, but make sure you have both public and private key in .ssh, or confusion ensues. Note that when gitolite asks you to double check the "host gitolite" ssh stanza, you probably want to change hostname to $SLAVE, at least temporarily (if not, at least the checkout of the gitolite-admin repo will fail) You may want to copy .gitolite.rc from $MASTER when gitolite fires up an editor.
On $CLIENT copy the "gitolite" stanza of .ssh/config to gitolite-mirror to a stanza called e.g. gitolite-slave fix the hostname of the gitolite stanza so it points to $MASTER again.
On $MASTER, as gitolite user, make passphraseless ssh-key. Probably you should call it something like 'mirror'
Still on $MASTER. Add a stanza like the following to $gitolite_user/.ssh/config
host gitolite-mirror hostname $SLAVE identityfile ~/.ssh/mirrorrun
ssh gitolite-mirrorat least once to test and set up any "know_hosts" file.On $CLIENT change directory to a checkout of gitolite admin from $MASTER. Make sure it is up to date with respect origin
git pullEdit .git/config (or, in very recent git, use
git remote seturl --push --add) so that remote origin looks likefetch = +refs/heads/*:refs/remotes/origin/* url = gitolite:gitolite-admin pushurl = gitolite:gitolite-admin pushurl = gitolite-slave:gitolite-adminAdd a stanza
repo @all RW+ = mirror
to the bottom of your gitolite.conf Add mirror.pub to keydir.
Now overwrite the gitolite-admin repo on $SLAVE
git push -f
Note that empty repos will be created on $SLAVE for every repo on $MASTER.
The following one line post-update hook to any repos you want mirrored (see the gitolite documentation for how to automate this) You should not modify the post update hook of the gitolite-admin repo.
git push --mirror gitolite-mirror:$GL_REPO.git
Create repos as per normal in the gitolite-admin/conf/gitolite.conf. If you have set the auto post-update hook installation, then each repo will be mirrored. You should only push to $MASTER; any changes pushed to $SLAVE will be overwritten.
Recently I was asked how to read mps (old school linear programming input) files. I couldn't think of a completely off the shelf way to do, so I write a simple c program to use the glpk library.
Of course in general you would want to do something other than print it out again.
So this is in some sense a nadir for shell scripting. 2 lines that do
something out of 111. Mostly cargo-culted from cowpoke by ron, but
much less fancy. rsbuild foo.dsc should do the trick.
#!/bin/sh
# Start a remote sbuild process via ssh. Based on cowpoke from devscripts.
# Copyright (c) 2007-9 Ron <ron@debian.org>
# Copyright (c) David Bremner 2009 <david@tethera.net>
#
# Distributed according to Version 2 or later of the GNU GPL.
BUILDD_HOST=sbuild-host
BUILDD_DIR=var/sbuild #relative to home directory
BUILDD_USER=""
DEBBUILDOPTS="DEB_BUILD_OPTIONS=\"parallel=3\""
BUILDD_ARCH="$(dpkg-architecture -qDEB_BUILD_ARCH 2>/dev/null)"
BUILDD_DIST="default"
usage()
{
cat 1>&2 <<EOF
rsbuild [options] package.dsc
Uploads a Debian source package to a remote host and builds it using sbuild.
The following options are supported:
--arch="arch" Specify the Debian architecture(s) to build for.
--dist="dist" Specify the Debian distribution(s) to build for.
--buildd="host" Specify the remote host to build on.
--buildd-user="name" Specify the remote user to build as.
The current default configuration is:
BUILDD_HOST = $BUILDD_HOST
BUILDD_USER = $BUILDD_USER
BUILDD_ARCH = $BUILDD_ARCH
BUILDD_DIST = $BUILDD_DIST
The expected remote paths are:
BUILDD_DIR = $BUILDD_DIR
sbuild must be configured on the build host. You must have ssh
access to the build host as BUILDD_USER if that is set, else as the
user executing cowpoke or a user specified in your ssh config for
'$BUILDD_HOST'. That user must be able to execute sbuild.
EOF
exit $1
}
PROGNAME="$(basename $0)"
version ()
{
echo \
"This is $PROGNAME, version 0.0.0
This code is copyright 2007-9 by Ron <ron@debian.org>, all rights reserved.
Copyright 2009 by David Bremner <david@tethera.net>, all rights reserved.
This program comes with ABSOLUTELY NO WARRANTY.
You are free to redistribute this code under the terms of the
GNU General Public License, version 2 or later"
exit 0
}
for arg; do
case "$arg" in
--arch=*)
BUILDD_ARCH="${arg#*=}"
;;
--dist=*)
BUILDD_DIST="${arg#*=}"
;;
--buildd=*)
BUILDD_HOST="${arg#*=}"
;;
--buildd-user=*)
BUILDD_USER="${arg#*=}"
;;
--dpkg-opts=*)
DEBBUILDOPTS="DEB_BUILD_OPTIONS=\"${arg#*=}\""
;;
*.dsc)
DSC="$arg"
;;
--help)
usage 0
;;
--version)
version
;;
*)
echo "ERROR: unrecognised option '$arg'"
usage 1
;;
esac
done
dcmd rsync --verbose --checksum $DSC $BUILDD_USER$BUILDD_HOST:$BUILDD_DIR
ssh -t $BUILDD_HOST "cd $BUILDD_DIR && $DEBBUILDOPTS sbuild --arch=$BUILDD_ARCH --dist=$BUILDD_DIST $DSC"
I am currently making a shared library out of some existing C code, for eventual inclusion in Debian. Because the author wasn't thinking about things like ABIs and APIs, the code is not too careful about what symbols it exports, and I decided clean up some of the more obviously private symbols exported.
I wrote the following simple script because I got tired of running grep by hand. If you run it with
grep-symbols symbolfile *.c
It will print the symbols sorted by how many times they occur in the other arguments.
#!/usr/bin/perl
use strict;
use File::Slurp;
my $symfile=shift(@ARGV);
open SYMBOLS, "<$symfile" || die "$!";
# "parse" the symbols file
my %count=();
# skip first line;
$_=<SYMBOLS>;
while(<SYMBOLS>){
chomp();
s/^\s*([^\@]+)\@.*$/$1/;
$count{$_}=0;
}
# check the rest of the command line arguments for matches against symbols. Omega(n^2), sigh.
foreach my $file (@ARGV){
my $string=read_file($file);
foreach my $sym (keys %count){
if ($string =~ m/\b$sym\b/){
$count{$sym}++;
}
}
}
print "Symbol\t Count\n";
foreach my $sym (sort {$count{$a} <=> $count{$b}} (keys %count)){
print "$sym\t$count{$sym}\n";
}
- Updated Thanks to Peter Pöschl for pointing out the file slurp should not be in the inner loop.
So, a few weeks ago I wanted to play play some music. Amarok2 was only playing one track at time. Hmm, rather than fight with it, maybe it is time to investigate alternatives. So here is my story. Mac using friends will probably find this amusing.
minirok segfaults as soon I try to do something #544230
bluemingo seems to only understand mp3's
exaile didn't play m4a (these are ripped with faac, so no DRM) files out of the box. A small amount of googling didn't explain it.
mpd looks cool, but I didn't really want to bother with that amount of setup right now.
Quod Libet also seems to have some configuration issues preventing it from playing m4a's
I hate the interface of Audacious
mocp looks cool, like mpd but easier to set up, but crashes trying to play an m4a file. This looks a lot like #530373
qmmp + xmonad = user interface fail.
juk also seems not to play (or catalog) my m4a's
In the end I went back and had a second look at mpd, and I'm pretty happy with it, just using the command line client mpc right now. I intend to investigate the mingus emacs client for mpd at some point.
An emerging theme is that m4a on Linux is pain.
UPDATED It turns out that one problem was I needed gstreamer0.10-plugins-bad and gstreamer0.10-plugins-really-bad. The latter comes from debian-multimedia.org, and had a file conflict with the former in Debian unstable (bug #544667 apparently just fixed). Grabbing the version from testing made it work. This fixed at least rhythmbox, exhaile and quodlibet. Thanks to Tim-Philipp Müller for the solution.
I guess the point I missed at first was that so many of the players use gstreamer as a back end, so what looked like many bugs/configuration-problems was really one. Presumably I'd have to go through a similar process to get phonon working for juk.
So I had this brainstorm that I could get sticky labels approximately the right size and paste current gpg key info to the back of business cards. I played with glabels for a bit, but we didn't get along. I decided to hack something up based on the gpg-key2ps script in the signing-party package. I'm not proud of the current state; it is hard-coded for one particular kind of labels I have on my desk, but it should be easy to polish if anyone thinks this is and idea worth pursuing. The output looks like this. Note that the boxes are just for debugging.
There have been several posts on Planet Debian planet lately about Netbooks. Biella Coleman pondered the wisdom of buying a Lenovo IdeaPad S10, and Russell talked about the higher level question of what kind of netbook one should buy.
I'm currently thinking of buying a netbook for my wife to use in her continuing impersonation of a student. So, to please Russell, what do I care about?
- Comfortably running
- emacs
- latex
- openoffice
- iceweasel
- vlc
- Debian support
- a keyboard my wife can more or less touch type on.
- a matte screen
- build quality
I think a 10" model is required to get a decentish keyboard, and a hard-drive would be just easier when she discovers that another 300M of diskspaced is needed for some must-have application. I realize in Tokyo and Seoul they probably call these "desktop replacements", but around here these are aparently "netbooks" :)
Some options I'm considering (prices are in Canadian dollars, before taxes). Unless I missed something, these are all Intel Atom N270/N280, 160G HD, 1G RAM.
| Mfr | Model | Price | Mass (6 cell) | Pros | Cons |
| Lenovo | S10-2 | $400 | 1.22 | build quality, | wireless is a bit of a hassle (1) |
| | S10e | $400 | 1.38 | express card slot | |
| Dell | Mini 10v | $350 | 1.33 | price | memory upgrade is a hassle (2) |
| Asus | 1000HE | $450 | 1.45kg | well supported in debian (3), N280 | price |
| Asus | 1005HA | $450 | 1.27kg | wireless OK, ore likes the keyboard, | wired ethernet is very new (4), price |
| MSI | U100 | $400 | 1.3kg | "just works" according debian wiki | availability (5) |
Currently needs non-free driver broadcom-sta. On the other hand, the broadcom-sta maintainer has one. Also, bt43 is supposed to support them pretty soonish.
There are web pages describing how, but it looks like it probably voids your warranty, since you have to crack the case open.
I don't know if the driver situation is so much better (since asus switches chipsets within the same model), but there is an active group of people using Debian on these machines.
Very new as in currently needs patches to the Linux kernel.
These seem to be end-of-lifed; stock is very limited. Price is for a six cell battery for better comparison; 9-cell is about $50 more.
So last night I did something I didn't think I would do, I bought an downloadable album in MP3 format. Usually I prefer to buy lossless FLAC, but after a good show I tend to be in an acquisitive mood. The band was using isongcard.com. The gimick is you give your money to the band at the show and the give you a card with a code on it that allows you to download the album. I can see the attraction from the band's point of view: you actually make the sales, rather than a vague possibility that someone might go to your site later, and you don't have to carry crates of CDs around with you. From a consumer point of view, it is not quite as satisfying as carting off a CD, but maybe I am in the last generation that feels that way.
At first I thought this might have something to do with itunes, which discouraged me because I have to borrow a computer (ok, borrow it from my wife, downstairs, but still) in order to run Windows, to run itunes. But when I saw the self printed cards with hand-printed 16 digit pin numbers, I thought there might be hope. And indeed, it turns out to be quite any-browser/any-OS-friendly. I downloaded the songs using arora, and they are ready to go. I have only two complaints (aside from the FLAC thing).
I had to download each song individually. Some kind of archive (say zip) would have been preferable.
The songs didn't have any tags.
So overall, kudos to isongcard (and good luck fending off Apple's lawyers about your name).
Fourth in a series (git-sync-experiments, git-sync-experiments2, git-sync-experiments3) of completely unscientific experiments to try and figure out the best way to sync many git repos.
I wanted to see how bundles worked, and if there was some potential for speedup versus mr. The following unoptimized script is about twice as fast as mr in updating 10 repos. Of course is not really doing exactly the right thing (since it only looks at HEAD), but it is a start maybe. Of course, maybe the performance difference has nothing to do with bundles. Anyway IPC::PerlSSH is nifty.
#!/usr/bin/perl
use strict;
use File::Slurp;
use IPC::PerlSSH;
use Git;
my %config;
eval(read_file('config.pl'));
die $@ if $@;
my $ips= IPC::PerlSSH->new(Host=>$config{host});
$ips->eval("use Git; use File::Temp qw (tempdir); use File::Slurp;");
$ips->eval('${main::tempdir}=tempdir();');
$ips->store( "bundle",
q{my $prefix=shift;
my $name=shift;
my $ref=shift;
chomp($ref);
my $repo=Git->repository($prefix.$name.'.git');
my $bfile="${main::tempdir}/${name}.bundle";
eval {$repo->command('bundle','create',
$bfile,
$ref.'..HEAD'); 1}
or do { return undef };
my $bits=read_file($bfile);
print STDERR ("got ",length($bits),"\n");
return $bits;
}
);
foreach my $pair (@{$config{repos}}){
my ($local,$remote)=@{$pair};
my $bname=$local.'.bundle';
$bname =~ s|/|_|;
$bname =~ s|^\.|@|;
my $repo=Git->repository($config{localprefix}.$local);
# force some commit to be bundled, just for testing
my $head=$repo->command('rev-list','--max-count=1', 'origin/HEAD^');
my $bits=$ips->call('bundle',$config{remoteprefix},$remote,$head);
write_file($bname, {binmode => ':raw'}, \$bits);
$repo->command_noisy('fetch',$ENV{PWD}.'/'.$bname,'HEAD');
}
The config file is just a hash
%config=(
host=>'hostname',
localprefix=>'/path/',
remoteprefix=>'/path/git/'
repos=>[
[qw(localdir remotedir)],
]
)
In order to have pretty highlighted oz code in HTML and TeX, I defined a simple language definition "oz.lang"
keyword = "andthen|at|attr|case|catch|choice|class|cond",
"declare|define|dis|div|do|else|elsecase|",
"elseif|elseof|end|fail|false|feat|finally|for",
"from|fun|functor|if|import|in|local|lock|meth",
"mod|not|of|or|orelse|prepare|proc|prop|raise",
"require|self|skip|then|thread|true|try|unit"
meta delim "<" ">"
cbracket = "{|}"
comment start "%"
symbol = "~","*","(",")","-","+","=","[","]","#",":",
",",".","/","?","&","<",">","\|"
atom delim "'" "'" escape "\\"
atom = '[a-z][[:alpha:][:digit:]]*'
variable delim "`" "`" escape "\\"
variable = '[A-Z][[:alpha:][:digit:]]*'
string delim "\"" "\"" escape "\\"
The meta tags are so I can intersperse EBNF notation in with oz code. Unfortunately source-highlight seems a little braindead about e.g. environment variables, so I had to wrap the invocation in a script
#!/bin/sh
HLDIR=$HOME/config/source-highlight
source-highlight --style-file=$HLDIR/default.style --lang-map=$HLDIR/lang.map $*
The final pieces of the puzzle is a customized lang.map file that tells source-highlight to use "oz.lang" for "foo.oz" and a default.style file that defines highlighting for "meta" text.
UPDATED An improved version of this lang file is now in source-highlight, so this hackery is now officially obsolete.
So I have been getting used to madduck's workflow for topgit and debian packaging, and one thing that bugged me a bit was all the steps required to to build. I tend to build quite a lot when debugging, so I wrote up a quick and dirty script to
- export a copy of the master branch somewhere
- export the patches from topgit
- invoke debuild
I don't claim this is anywhere ready production quality, but maybe it helps someone.
Assumptions (that I remember)
- you use the workflow above
- you use pristine tar for your original tarballs
- you invoke the script (I call it tg-debuild) from somewhere in your work tree
Here is the actual script:
#!/bin/sh
set -x
if [ x$1 = x-k ]; then
keep=1
else
keep=0
fi
WORKROOT=/tmp
WORKDIR=`mktemp -d $WORKROOT/tg-debuild-XXXX`
# yes, this could be nicer
SOURCEPKG=`dpkg-parsechangelog | grep ^Source: | sed 's/^Source:\s*//'`
UPSTREAM=`dpkg-parsechangelog | grep ^Version: | sed -e 's/^Version:\s*//' -e s/-[^-]*//`
ORIG=$WORKDIR/${SOURCEPKG}_${UPSTREAM}.orig.tar.gz
pristine-tar checkout $ORIG
WORKTREE=$WORKDIR/$SOURCEPKG-$UPSTREAM
CDUP=`git rev-parse --show-cdup`
GDPATH=$PWD/$CDUP/.git
DEST=$PWD/$CDUP/../build-area
git archive --prefix=$WORKTREE/ --format=tar master | tar xfP -
GIT_DIR=$GDPATH make -C $WORKTREE -f debian/rules tg-export
cd $WORKTREE && GIT_DIR=$GDPATH debuild
if [ $?==0 -a -d $DEST ]; then
cp $WORKDIR/*.deb $WORKDIR/*.dsc $WORKDIR/*.diff.gz $WORKDIR/*.changes $DEST
fi
if [ $keep = 0 ]; then
rm -fr $WORKDIR
fi
Scenario
You are maintaining a debian package with topgit. You have a topgit patch against version k and it is has been merged into upstream version m. You want to "disable" the topgit branch, so that patches are not auto-generated, but you are not brave enough to just
tg delete feature/foo
You are brave enough to follow the instructions of a random blog post.
Checking your patch has really been merged upstream
This assumes that you tags upstream/j for version j.
git checkout feature/foo
git diff upstream/k
For each file foo.c modified in the output about, have a look at
git diff upstream/m foo.c
This kindof has to be a manual process, because upstream could easily have modified your patch (e.g. formatting).
The semi-destructive way
Suppose you really never want to see that topgit branch again.
git update-ref -d refs/topbases/feature/foo
git checkout master
git branch -M feature/foo merged/foo
The non-destructive way.
After I worked out the above, I realized that all I had to do was make an explicit list of topgit branches that I wanted exported. One minor trick is that the setting seems to have to go before the include, like this
TG_BRANCHES=debian/bin-makefile debian/libtoolize-lib debian/test-makefile
-include /usr/share/topgit/tg2quilt.mk
Conclusions
I'm not really sure which approach is best yet. I'm going to start with the non-destructive one and see how that goes.
Updated Madduck points to a third, more sophisticated approach in Debian BTS.
I wanted to report a success story with topgit which is a rather new patch queue managment extension for git. If that sounds like gibberish to you, this is probably not the blog entry you are looking for.
Some time ago I decided to migrate the debian packaging of bibutils to topgit. This is not a very complicated package, with 7 quilt patches applied to upstream source. Since I don't have any experience to go on, I decided to follow Martin 'madduck' Krafft's suggestion for workflow.
It all looks a bit complicated (madduck will be the first to agree),
but it forced me to think about which patches were intended to go
upstream and which were not. At the end of the conversion I had 4
patches that were cleanly based on upstream, and (perhaps most
importantly for lazy people like me), I could send them upstream with
tg mail. I did that, and a few days later, Chris Putnam sent me a
new upstream release incorporating all of those patches. Of course, now I have
to package this new upstream release :-).
The astute reader might complain that this is more about me developing
half-decent workflow, and Chris being a great guy, than about any
specific tool. That may be true, but one thing I have discovered
since I started using git is that tools that encourage good workflow
are very nice. Actually, before I started using git, I didn't even use
the word workflow. So I just wanted to give a public thank you to
pasky for writing topgit and to madduck for pushing it into debian,
and thinking about debian packaging with topgit.
Recently I suggested to some students that they could use the Gnu Linear Programming Toolkit from C++. Shortly afterwards I thought I had better verify that I had not just sent people on a hopeless mission. To test things out, I decided to try using GLPK as part of an ongoing project with Lars Schewe
The basic idea of this example is to use glpk to solve an integer program with row generation.
The main hurdle (assuming you want to actually write object oriented c++) is how to make the glpk callback work in an object oriented way. Luckily glpk provides a pointer "info" that can be passed to the solver, and which is passed back to the callback routine. This can be used to keep track of what object is involved.
Here is the class header
#ifndef GLPSOL_HH
#define GLPSOL_HH
#include "LP.hh"
#include "Vektor.hh"
#include "glpk.h"
#include "combinat.hh"
namespace mpc {
class GLPSol : public LP {
private:
glp_iocp parm;
static Vektor<double> get_primal_sol(glp_prob *prob);
static void callback(glp_tree *tree, void *info);
static int output_handler(void *info, const char *s);
protected:
glp_prob *root;
public:
GLPSol(int columns);
~GLPSol() {};
virtual void rowgen(const Vektor<double> &candidate) {};
bool solve();
bool add(const LinearConstraint &cnst);
};
}
#endif
The class LP is just an abstract base class (like an interface for
java-heads) defining the add method. The method rowgen is virtual
because it is intended to be overridden by a subclass if row
generation is actually required. By default it does nothing.
Notice that the callback method here is static; that means it is
essentially a C function with a funny name. This will be the
function that glpk calls when it wants from help.
#include <assert.h>
#include "GLPSol.hh"
#include "debug.hh"
namespace mpc{
GLPSol::GLPSol(int columns) {
// redirect logging to my handler
glp_term_hook(output_handler,NULL);
// make an LP problem
root=glp_create_prob();
glp_add_cols(root,columns);
// all of my variables are binary, my objective function is always the same
// your milage may vary
for (int j=1; j<=columns; j++){
glp_set_obj_coef(root,j,1.0);
glp_set_col_kind(root,j,GLP_BV);
}
glp_init_iocp(&parm);
// here is the interesting bit; we pass the address of the current object
// into glpk along with the callback function
parm.cb_func=GLPSol::callback;
parm.cb_info=this;
}
int GLPSol::output_handler(void *info, const char *s){
DEBUG(1) << s;
return 1;
}
Vektor<double> GLPSol::get_primal_sol(glp_prob *prob){
Vektor<double> sol;
assert(prob);
for (int i=1; i<=glp_get_num_cols(prob); i++){
sol[i]=glp_get_col_prim(prob,i);
}
return sol;
}
// the callback function just figures out what object called glpk and forwards
// the call. I happen to decode the solution into a more convenient form, but
// you can do what you like
void GLPSol::callback(glp_tree *tree, void *info){
GLPSol *obj=(GLPSol *)info;
assert(obj);
switch(glp_ios_reason(tree)){
case GLP_IROWGEN:
obj->rowgen(get_primal_sol(glp_ios_get_prob(tree)));
break;
default:
break;
}
}
bool GLPSol::solve(void) {
int ret=glp_simplex(root,NULL);
if (ret==0)
ret=glp_intopt(root,&parm);
if (ret==0)
return (glp_mip_status(root)==GLP_OPT);
else
return false;
}
bool GLPSol::add(const LinearConstraint&cnst){
int next_row=glp_add_rows(root,1);
// for mysterious reasons, glpk wants to index from 1
int indices[cnst.size()+1];
double coeff[cnst.size()+1];
DEBUG(3) << "adding " << cnst << std::endl;
int j=1;
for (LinearConstraint::const_iterator p=cnst.begin();
p!=cnst.end(); p++){
indices[j]=p->first;
coeff[j]=(double)p->second;
j++;
}
int gtype=0;
switch(cnst.type()){
case LIN_LEQ:
gtype=GLP_UP;
break;
case LIN_GEQ:
gtype=GLP_LO;
break;
default:
gtype=GLP_FX;
}
glp_set_row_bnds(root,next_row,gtype,
(double)cnst.rhs(),(double)cnst.rhs());
glp_set_mat_row(root,
next_row,
cnst.size(),
indices,
coeff);
return true;
}
}
All this is a big waste of effort unless we actually do some row generation. I'm not especially proud of the crude rounding I do here, but it shows how to do it, and it does, eventually solve problems.
#include "OMGLPSol.hh"
#include "DualGraph.hh"
#include "CutIterator.hh"
#include "IntSet.hh"
namespace mpc{
void OMGLPSol::rowgen(const Vektor<double>&candidate){
if (diameter<=0){
DEBUG(1) << "no path constraints to generate" << std::endl;
return;
}
DEBUG(3) << "Generating paths for " << candidate << std::endl;
// this looks like a crude hack, which it is, but motivated by the
// following: the boundary complex is determined only by the signs
// of the bases, which we here represent as 0 for - and 1 for +
Chirotope chi(*this);
for (Vektor<double>::const_iterator p=candidate.begin();
p!=candidate.end(); p++){
if (p->second > 0.5) {
chi[p->first]=SIGN_POS;
} else {
chi[p->first]=SIGN_NEG;
}
}
BoundaryComplex bc(chi);
DEBUG(3) << chi;
DualGraph dg(bc);
CutIterator pathins(*this,candidate);
int paths_found=
dg.all_paths(pathins,
IntSet::lex_set(elements(),rank()-1,source_facet),
IntSet::lex_set(elements(),rank()-1,sink_facet),
diameter-1);
DEBUG(1) << "row generation found " << paths_found << " realized paths\n";
DEBUG(1) << "effective cuts: " << pathins.effective() << std::endl;
}
void OMGLPSol::get_solution(Chirotope &chi) {
int nv=glp_get_num_cols(root);
for(int i=1;i<=nv;++i) {
int val=glp_mip_col_val(root,i);
chi[i]=(val==0 ? SIGN_NEG : SIGN_POS);
}
}
}
So ignore the problem specific way I generate constraints, the key
remaining piece of code is CutIterator which filters the generated
constraints to make sure they actually cut off the candidate
solution. This is crucial, because row generation must not add
constraints in the case that it cannot improve the solution, because
glpk assumes that if the user is generating cuts, the solver doesn't
have to.
#ifndef PATH_CONSTRAINT_ITERATOR_HH
#define PATH_CONSTRAINT_ITERATOR_HH
#include "PathConstraint.hh"
#include "CNF.hh"
namespace mpc {
class CutIterator : public std::iterator<std::output_iterator_tag,
void,
void,
void,
void>{
private:
LP& _list;
Vektor<double> _sol;
std::size_t _pcount;
std::size_t _ccount;
public:
CutIterator (LP& list, const Vektor<double>& sol) : _list(list),_sol(sol), _pcount(0), _ccount(0) {}
CutIterator& operator=(const Path& p) {
PathConstraint pc(p);
_ccount+=pc.appendTo(_list,&_sol);
_pcount++;
if (_pcount %10000==0) {
DEBUG(1) << _pcount << " paths generated" << std::endl;
}
return *this;
}
CutIterator& operator*() {return *this;}
CutIterator& operator++() {return *this;}
CutIterator& operator++(int) {return *this;}
int effective() { return _ccount; };
};
}
#endif
Oh heck, another level of detail; the actual filtering actually
happens in the appendTo method the PathConstraint class. This is
just computing the dot product of two vectors. I would leave it as an
exercise to the readier, but remember some fuzz is neccesary to to
these kinds of comparisons with floating point numbers. Eventually,
the decision is made by the following feasible method of the
LinearConstraint class.
bool feasible(const
Vektor<double> & x){ double sum=0; for (const_iterator
p=begin();p!=end(); p++){ sum+= p->second*x.at(p->first); }
switch (type()){
case LIN_LEQ:
return (sum <= _rhs+epsilon);
case LIN_GEQ:
return (sum >= _rhs-epsilon);
default:
return (sum <= _rhs+epsilon) &&
(sum >= _rhs-epsilon);
}
}
I have been meaning to fix this up for a long time, but so far real work keeps getting in the way. The idea is that C-C t brings you to this week's time tracker buffer, and then you use (C-c C-x C-i/C-c C-x C-o) to start and stop timers.
The only even slightly clever is stopping the timer and saving on quitting emacs, which I borrowed from the someone on the net.
- Updated dependence on mhc removed.
- Updated 2009/01/05 Fixed week-of-year calculation
The main guts of the hack are here.
The result might look like the this (works better in emacs org-mode. C-c C-x C-d for a summary)
Third in a series (git-sync-experiments, git-sync-experiments2) of completely unscientific experiments to try and figure out the best way to sync many git repos.
If you want to make many ssh connections to a given host, then the first thing you need to do is turn on multiplexing. See the ControlPath and ControlMaster options in ssh config
Presuming that is not fast enough, then one option is to make many parallel connections (see e.g. git-sync-experiments2). But this won't scale very far.
In this week I consider the possibilities of running a tunneled socket to a remote git-daemon
ssh -L 9418:localhost:9418 git-host.domain.tld git-daemon --export-all
Of course from a security point of view this is awful, but I did it anyway, at least temporarily.
Running my "usual" test of git pull in 15 up-to-date repos, I get 3.7s
versus about 5s with the multiplexing. So, 20% improvement, probably not
worth the trouble. In both cases I just run a shell script like
cd repo1 && git pull && cd ..
cd repo2 && git pull && cd ..
cd repo3 && git pull && cd ..
cd repo4 && git pull && cd ..
cd repo5 && git pull && cd ..
In a recent blog post, Kai complained about various existing tools for marking up email in HTML. He also asked for pointers to other tools. Since he didn't specify good tools :-), I took the opportunity to promote my work in progress plugin for ikiwiki to do that very thing.
When asked about demo sites, I realized that my blog doesn't actually use threaded comments, yet, so made a poor demo.
Follow the link and you will find one of the mailboxes from the distribution, mostly a few posts from one of the debian lists.
The basic idea is to use the Email::Thread perl module to get a forest of thread trees, and then walk those generating output.
I think it would be fairly easy to make a some kind of mutt-like index using the essentially same tree walking code. Not that I'm volunteering immediately mind you, I have to replys to comments on my blog working (which is the main place I use this plugin right now).
RSS readers are better than obsessively checking 18 or so web sites myself, but they seem to share one very annoying feature. They assume I read news/rss on only one machine, and I have to manually mark off which articles I have already read on a different machine.
Similarly, nntp readers (that I know about) have only a local idea of what is read and not read. For me, this makes reading high volume lists via gmane almost unbearable.
Am I the only one that wastes time on more than one computer?
I have been thinking about ways to speed multiple remote git on the same hosts. My starting point is mr, which does the job, but is a bit slow. I am thinking about giving up some generality for some speed. In particular it seems like it ought to be possible to optimize for the two following use cases:
- many repos are on the same host
- mostly nothing needs updating.
For my needs, mr is almost fast enough, but I can see it getting
annoying as I add repos (I currently have 11, and mr update takes
about 5 seconds; I am already running ssh multiplexing).
I am also thinking about the needs of the Debian
Perl Modules Team, which would have over
900 git repos if the current setup was converted to one git repo per
module.
My first attempt, using perl module Net::SSH::Expect to keep an ssh channel open can be scientifically classified as "utter fail", since Net::SSH::Expect takes about 1 second to round trip "/bin/true".
Initial experiments using IPC::PerlSSH are more promising. The following script grabs the head commit in 11 repos in about 0.5 seconds. Of course, it still doesn't do anything useful, but I thought I would toss this out there in case there already exists a solution to this problem I don't know about.
#!/usr/bin/perl
use IPC::PerlSSH;
use Getopt::Std;
use File::Slurp;
my %config;
eval( "\%config=(".read_file(shift(@ARGV)).")");
die "reading configuration failed: $@" if $@;
my $ips= IPC::PerlSSH->new(Host=>$config{host});
$ips->eval("use Git");
$ips->store( "ls_remote", q{my $repo=shift;
return Git::command_oneline('ls-remote',$repo,'HEAD');
} );
foreach $repo (@{$config{repos}}){
print $ips->call("ls_remote",$repo);
}
P.S. If you google for "mr joey hess", you will find a Kiss tribute band called Mr. Speed, started by Joe Hess"
P.P.S. Hello planet debian!
In a previous post I complained that mr was too slow. madduck pointed me to the "-j" flag, which runs updates in parallel. With -j 5, my 11 repos update in 1.2s, so this is probably good enough to put this project on the back burner until I get annoyed again.
I have the feeling that the "right solution" (TM) involves running either git-daemon or something like it on the remote host. The concept would be to set up a pair of file descriptors connected via ssh to the remote git-daemon, and have your local git commands talk to that pair of file descriptors instead of a socket. Alas, that looks like a bit of work to do, if it is even possible.
So I spent a couple hours editing Haskell. So of course I had to spend at least that long customizing emacs. My particular interest is in so called literate haskell code that intersperses LaTeX and Haskell.
The first step is to install haskell-mode and mmm-mode.
apt-get install haskell-mode mmm-mode
Next, add something like the following to your .emacs
(load-library "haskell-site-file")
;; Literate Haskell [requires MMM]
(require 'mmm-auto)
(require 'mmm-haskell)
(setq mmm-global-mode 'maybe)
(add-to-list 'mmm-mode-ext-classes-alist
'(latex-mode "\\.lhs$" haskell))
Now I want to think about these files as LaTeX with bits of Haskell in them, so
I tell auctex that .lhs files belong to it (also in .emacs)
(add-to-list 'auto-mode-alist '("\\.lhs\\'" . latex-mode))
(eval-after-load "tex"
'(progn
(add-to-list 'LaTeX-command-style '("lhs" "lhslatex"))
(add-to-list 'TeX-file-extensions "lhs")))
In order that the
\begin{code}
\end{code}
environment is typeset nicely, I want any latex file that uses the
style lhs to be processed with the script lhslatex (hence the
messing with LaTeX-command-style). At the moment I just have an
empty lhs.sty, but in principle it could contain useful definitions,
e.g. the output from lhs2TeX on a file containing only
%include polycode.fmt
The current version of lhslatex is a bit crude. In particular it assumes you want to run pdflatex.
The upshot is that you can use AUCTeX mode in the LaTeX part of the buffer
(i.e. TeX your buffer) and haskell mode in the \begin{code}\end{code} blocks
(i.e. evaluate the same buffer as Haskell).
To convert an svn repository containing only "/debian" to something compatible with git-buildpackage, you need to some work. Luckily zack already figured out how.
#
package=bibutils
version=3.40
mkdir $package
cd $package
git-svn init --stdlayout --no-metadata svn://svn.debian.org/debian-science/$package
git-svn fetch
# drop upstream branch from svn
git-branch -d -r upstream
# create a new upstream branch based on recipe from zack
#
git-symbolic-ref HEAD refs/heads/upstream
git rm --cached -r .
git commit --allow-empty -m 'initial upstream branch'
git checkout -f master
git merge upstream
git-import-orig --pristine-tar --no-dch ../tarballs/${package}_${version}.orig.tar.gz
If you forget to use --authors-file=file then you can fix up your
mistakes later with something like the following. Note that after
some has cloned your repo, this makes life difficult for them.
#!/bin/sh
project=vrr
name="David Bremner"
email="bremner@unb.ca"
git clone alioth.debian.org:/git/debian-science/packages/$project $project.new
cd $project.new
git branch upstream origin/upstream
git branch pristine-tar origin/pristine-tar
git-filter-branch --env-filter "export GIT_AUTHOR_EMAIL='bremner@unb.ca' GIT_AUTHOR_NAME='David Bremner'" master upstream pristine-tar